



Natural language processing (NLP) is a branch of Artificial Intelligence (AI) that helps computers understand, interpret and manipulate human language. NLP draws from many disciplines, including computer science and computational linguistics, in its pursuit to fill the gap between human communication and computer understanding.
While natural language processing isn’t a new science, the technology is rapidly advancing thanks to an increased interest in human-to-machine communications, plus an availability of big data, powerful computing and enhanced algorithms.
As a human, you may speak and write in English, Spanish or Chinese. But a computer’s native language – known as machine code or machine language – is largely incomprehensible to most people. At your device’s lowest levels, communication occurs not with words but through millions of zeros and ones that produce logical actions.
Indeed, programmers used punch cards to communicate with the first computers 70 years ago. This manual and arduous process was understood by a relatively small number of people. Now you can say, “Alexa, I like this song,” and a device playing music in your home will lower the volume and reply, “OK. Rating saved,” in a human-like voice. Then it adapts its algorithm to play that song – and others like it – the next time you listen to that music station.
Let’s take a closer look at that interaction. Your device activated when it heard you speak, understood the unspoken intent in the comment, executed an action and provided feedback in a well-formed English sentence, all in the space of about five seconds. The complete interaction was made possible by NLP, along with other AI elements such as machine learning and deep learning.
What is Natural Language Processing?
History
The history of natural language processing generally started in the 1950s, although work can be found from earlier periods. In 1950, Alan Turing published an article titled "Intelligence" which proposed what is now called the Turing test as a criterion of intelligence.
1950
The Georgetown experiment in 1954 involved fully automatic translation of more than sixty Russian sentences into English. The authors claimed that within three or five years, machine translation would be a solved problem.
1960
However, real progress was much slower, and after the ALPAC report in 1966, which found that ten-year-long research had failed to fulfill the expectations, funding for machine translation was dramatically reduced. Little further research in machine translation was conducted until the late 1980s, when the first statistical machine translation systems were developed. Some notably successful natural language processing systems developed in the 1960s were SHRDLU, a natural language system working in restricted "blocks worlds" with restricted vocabularies, and ELIZA, a simulation of a Rogerian psychotherapist, written by Joseph Weizenbaum between 1964 and 1966. Using almost no information about human thought or emotion, ELIZA sometimes provided a startlingly human-like interaction. When the "patient" exceeded the very small knowledge base, ELIZA might provide a generic response, for example, responding to "My head hurts" with "Why do you say your head hurts?".
1970
During the 1970s, many programmers began to write "conceptual ontologies", which structured real-world information into computer-understandable data. Examples are MARGIE (Schank, 1975), SAM (Cullingford, 1978), PAM (Wilensky, 1978), TaleSpin (Meehan, 1976), QUALM (Lehnert, 1977), Politics (Carbonell, 1979), and Plot Units (Lehnert 1981). During this time, many chatbots were written including PARRY, Racter, and Jabberwacky.
1980Up to the 1980s, most natural language processing systems were based on complex sets of hand-written rules. Starting in the late 1980s, however, there was a revolution in natural language processing with the introduction of machine learning algorithms for language processing. This was due to both the steady increase in computational power (see Moore's law) and the gradual lessening of the dominance of Chomskyantheories of linguistics (e.g. transformational grammar), whose theoretical underpinnings discouraged the sort of corpus linguistics that underlies the machine-learning approach to language processing. Some of the earliest-used machine learning algorithms, such as decision trees, produced systems of hard if-then rules similar to existing hand-written rules. However, part-of-speech tagging introduced the use of hidden Markov models to natural language processing, and increasingly, research has focused on statistical models, which make soft, probabilistic decisions based on attaching real-valued weights to the features making up the input data. The cache language models upon which many speech recognition systems now rely are examples of such statistical models. Such models are generally more robust when given unfamiliar input, especially input that contains errors (as is very common for real-world data), and produce more reliable results when integrated into a larger system comprising multiple subtasks.
1990 to Current
Many of the notable early successes occurred in the field of machine translation, due especially to work at IBM Research, where successively more complicated statistical models were developed. These systems were able to take advantage of existing multilingual textual corpora that had been produced by the Parliament of Canada and the European Union as a result of laws calling for the translation of all governmental proceedings into all official languages of the corresponding systems of government. However, most other systems depended on corpora specifically developed for the tasks implemented by these systems, which was (and often continues to be) a major limitation in the success of these systems. As a result, a great deal of research has gone into methods of more effectively learning from limited amounts of data.
Recent research has increasingly focused on unsupervised and semi-supervised learning algorithms. Such algorithms are able to learn from data that has not been hand-annotated with the desired answers, or using a combination of annotated and non-annotated data. Generally, this task is much more difficult than supervised learning, and typically produces less accurate results for a given amount of input data. However, there is an enormous amount of non-annotated data available (including, among other things, the entire content of the World Wide Web), which can often make up for the inferior results if the algorithm used has a low enough time complexity to be practical.
In the 2010s, representation learning and deep neural network-style machine learning methods became widespread in natural language processing, due in part to a flurry of results showing that such techniques can achieve state-of-the-art results in many natural language tasks, for example in language modeling, parsing, and many others. Popular techniques include the use of word embeddings to capture semantic properties of words, and an increase in end-to-end learning of a higher-level task (e.g., question answering) instead of relying on a pipeline of separate intermediate tasks (e.g., part-of-speech tagging and dependency parsing). In some areas, this shift has entailed substantial changes in how NLP systems are designed, such that deep neural network-based approaches may be viewed as a new paradigm distinct from statistical natural language processing. For instance, the term neural machine translation (NMT) emphasizes the fact that deep learning-based approaches to machine translation directly learn sequence-to-sequence transformations, obviating the need for intermediate steps such as word alignment and language modeling that were used in statistical machine translation (SMT).
Why is NLP important?
Large volumes of textual data
Natural language processing helps computers communicate with humans in their own language and scales other language-related tasks. For example, NLP makes it possible for computers to read text, hear speech, interpret it, measure sentiment and determine which parts are important.
Today’s machines can analyze more language-based data than humans, without fatigue and in a consistent, unbiased way. Considering the staggering amount of unstructured data that’s generated every day, from medical records to social media, automation will be critical to fully analyze text and speech data efficiently.
Structuring a highly unstructured data sourceHuman language is astoundingly complex and diverse. We express ourselves in infinite ways, both verbally and in writing. Not only are there hundreds of languages and dialects, but within each language is a unique set of grammar and syntax rules, terms and slang. When we write, we often misspell or abbreviate words, or omit punctuation. When we speak, we have regional accents, and we mumble, stutter and borrow terms from other languages.
While supervised and unsupervised learning, and specifically deep learning, are now widely used for modeling human language, there’s also a need for syntactic and semantic understanding and domain expertise that are not necessarily present in these machine learning approaches. NLP is important because it helps resolve ambiguity in language and adds useful numeric structure to the data for many downstream applications, such as speech recognition or text analytics.
Source: Natural Language Process in 10 Minutes | NLP | Turorial - Edureka
How does NLP work?
Natural language processing includes many different techniques for interpreting human language, ranging from statistical and machine learning methods to rules-based and algorithmic approaches. We need a broad array of approaches because the text- and voice-based data varies widely, as do the practical applications.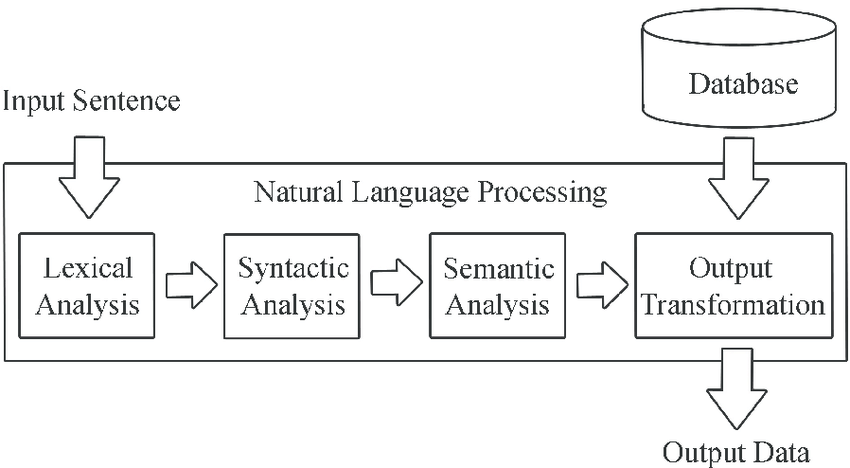
These underlying tasks are often used in higher-level NLP capabilities, such as:
- Content categorization. A linguistic-based document summary, including search and indexing, content alerts and duplication detection.
- Topic discovery and modeling. Accurately capture the meaning and themes in text collections, and apply advanced analytics to text, like optimization and forecasting.
- Contextual extraction. Automatically pull structured information from text-based sources.
- Sentiment analysis. Identifying the mood or subjective opinions within large amounts of text, including average sentiment and opinion mining.
- Speech-to-text and text-to-speech conversion. Transforming voice commands into written text, and vice versa.
- Document summarization. Automatically generating synopses of large bodies of text.
- Machine translation. Automatic translation of text or speech from one language to another.
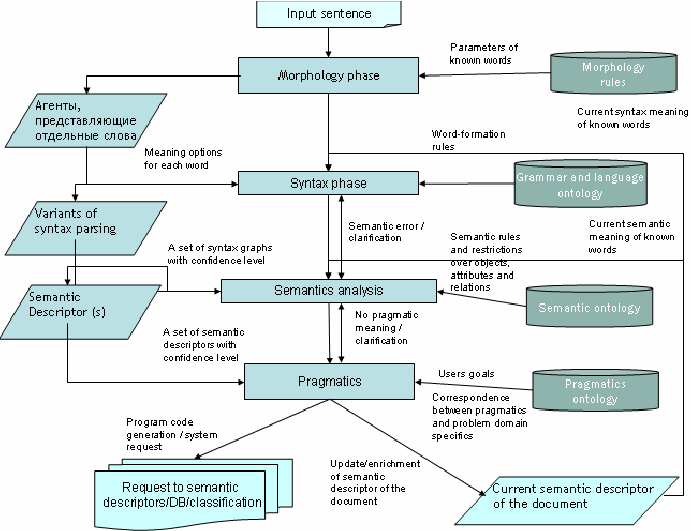
In all these cases, the overarching goal is to take raw language input and use linguistics and algorithms to transform or enrich the text in such a way that it delivers greater value.
7 Key Steps for getting started with Natural Language Processing (NLP) Project: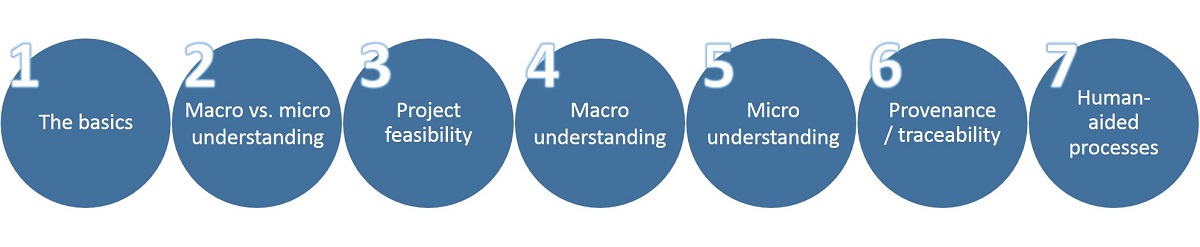
STEP 1: The Basics
The input to natural language processing will be a simple stream of Unicode characters (typically UTF-8). Basic processing will be required to convert this character stream into a sequence of lexical items (words, phrases, and syntactic markers) which can then be used to better understand the content.
The basics include:
- Structure extraction – identifying fields and blocks of content based on tagging
- Identify and mark sentence, phrase, and paragraph boundaries – these markers are important when doing entity extraction and NLP since they serve as useful breaks within which analysis occurs.
- Open source possibilities include the Lucene Segmenting Tokenizer and the Open NLP sentence and paragraphboundary detectors.
- Language identification – will detect the human language for the entire document and for each paragraph or sentence. Language detectors are critical to determine what linguistic algorithms and dictionaries to apply to the text.
- Open source possibilities include Google Language Detector or the Optimize Language Detector or the Chromium Compact Language Detector
- API methods include Bing Language Detection API, IBM Watson Language Identification, and Google Translation API for Language Detection
- Tokenization – to divide up character streams into tokens which can be used for further processing and understanding. Tokens can be words, numbers, identifiers or punctuation (depending on the use case)
- Open source tokenizers include the Lucene analyzers and the Open NLP Tokenizer.
- Basis Technology offers a fully featured language identification and text analytics package (called Rosette Base Linguistics) which is often a good first step to any language processing software. It contains language identification, tokenization, sentence detection, lemmatization, decompounding, and noun phrase extraction.
- NLP tools include tokenization, acronym normalization, lemmatization (English), sentence and phrase boundaries, entity extraction (all types but not statistical), and statistical phrase extraction. These tools can be used in conjunction with the Basis Technology’ solutions.
- Acronym normalization and tagging – acronyms can be specified as “I.B.M.” or “IBM” so these should be tagged and normalized.
- Lemmatization / Stemming – reduces word variations to simpler forms that may help increase the coverage of NLP utilities.
- Lemmatization uses a language dictionary to perform an accurate reduction to root words. Lemmatization is strongly preferred to stemming if available.
- Stemming uses simple pattern matching to simply strip suffixes of tokens (e.g. remove “s”, remove “ing”, etc.). The Open Source Lucene analyzers provide stemming for many languages.
- Decompounding – for some languages (typically Germanic, Scandinavian, and Cyrillic languages), compound words will need to be split into smaller parts to allow for accurate NLP.
- For example: “samstagmorgen” is “Saturday Morning” in German
- See Wiktionary German Compound Words for more examples
- Basis Technology's solution has decompounding.
- Entity extraction – identifying and extracting entities (people, places, companies, etc.) is a necessary step to simplify downstream processing. There are several different methods:
- Regex extraction – good for phone numbers, ID numbers (e.g. SSN, driver’s licenses, etc.), e-mail addresses, numbers, URLs, hashtags, credit card numbers, and similar entities.
- Dictionary extraction – uses a dictionary of token sequences and identifies when those sequences occur in the text. This is good for known entities, such as colors, units, sizes, employees, business groups, drug names, products, brands, and so on.
- Complex pattern-based extraction – good for people names (made of known components), business names (made of known components) and context-based extraction scenarios (e.g. extract an item based on its context) which are fairly regular in nature and when high precision is preferred over high recall.
- Statistical extraction – use statistical analysis to do context extraction. This is good for people names, company names, geographic entities which are not previously known and inside of well-structured text (e.g. academic or journalistic text). Statistical extraction tends to be used when high recall is preferred over high precision.
- Phrase extraction – extracts sequences of tokens (phrases) that have a strong meaning which is independent of the words when treated separately. These sequences should be treated as a single unit when doing NLP. For example, “Big Data” has a strong meaning which is independent of the words “big” and “data” when used separately. All companies have these sorts of phrases which are in common usage throughout the organization and are better treated as a unit rather than separately. Techniques to extract phrases include:
- Part of speech tagging – identifies phrases from noun or verb clauses
- Statistical phrase extraction - identifies token sequences which occur more frequently than expected by chance
- Hybrid - uses both techniques together and tends to be the most accurate method.
STEP 2: Decide on Macro versus Micro Understanding
Before you begin, you should decide what level of content understanding is required:
Macro Understanding – provides a general understanding of the document as a whole.
- Typically performed with statistical techniques
- It is used for: clustering, categorization, similarity, topic analysis, word clouds, and summarization
Micro Understanding – extracts understanding from individual phrases or sentences.
- Typically performed with NLP techniques
- It is used for: extracting facts, entities (see above), entity relationships, actions, and metadata fields
Note that, while micro understanding generally contributes to macro understanding, the two can be entirely different. For example, a résumé (or curriculum vitae) may identify a person, overall, as a Big Data Scientist [macro understanding] but it can also identify them as being fluent in French [micro understanding].
STEP 3: Decide If What You Want is Possible (Within A Reasonable Cost)
Not all natural language understanding (NLP) projects are possible within a reasonable cost and time.
STEP 4: Understand the Whole Document (Macro Understanding)
Once you have decided to embark on your NLP project, if you need a more holistic understanding of the document this is a “macro understanding.” This is useful for:
- Classifying / categorizing / organizing records
- Clustering records
- Extracting topics
- General sentiment analysis
- Record similarity, including finding similarities between different types of records (for example, job descriptions to résumés / CVs)
- Keyword / keyphrase extraction
- Duplicate and near-duplicate detection
- Summarization / key sentence extraction
- Semantic search
STEP 5: Extracting Facts, Entities, and Relationships (Micro Understanding)
Micro understanding is the extracting of individual entities, facts or relationships from the text. This is useful for (from easiest to hardest):
- Extracting acronyms and their definitions
- Extracting citation references to other documents
- Extracting key entities (people, company, product, dollar amounts, locations, dates). Note that extracting “key” entities is not the same as extracting “all” entities (there is some discrimination implied in selecting what entity is ‘key’)
- Extracting facts and metadata from full text when it’s not separately tagged in the web page
- Extracting entities with sentiment (e.g. positive sentiment towards a product or company)
- Identifying relationships such as business relationships, target / action / perpetrator, etc.
- Identifying compliance violations, statements which show possible violation of rules
- Extracting statements with attribution, for example, quotes from people (who said what)
- Extracting rules or requirements, such as contract terms, regulation requirements, etc.
Micro understanding must be done with syntactic analysis of the text. This means that order and word usage are important.
There are three approaches to performing extraction that provides micro understanding:
1. Top Down – determine Part of Speech, then understand and diagram the sentence into clauses, nouns, verbs, object and subject, modifying adjectives and adverbs, etc., then traverse this structure to identify structures of interest
- Advantages – can handle complex, never-seen-before structures and patterns
- Disadvantages – hard to construct rules, brittle, often fails with variant input, may still require substantial pattern matching even after parsing.
Sample top-down output from Google Cloud Natural Language API
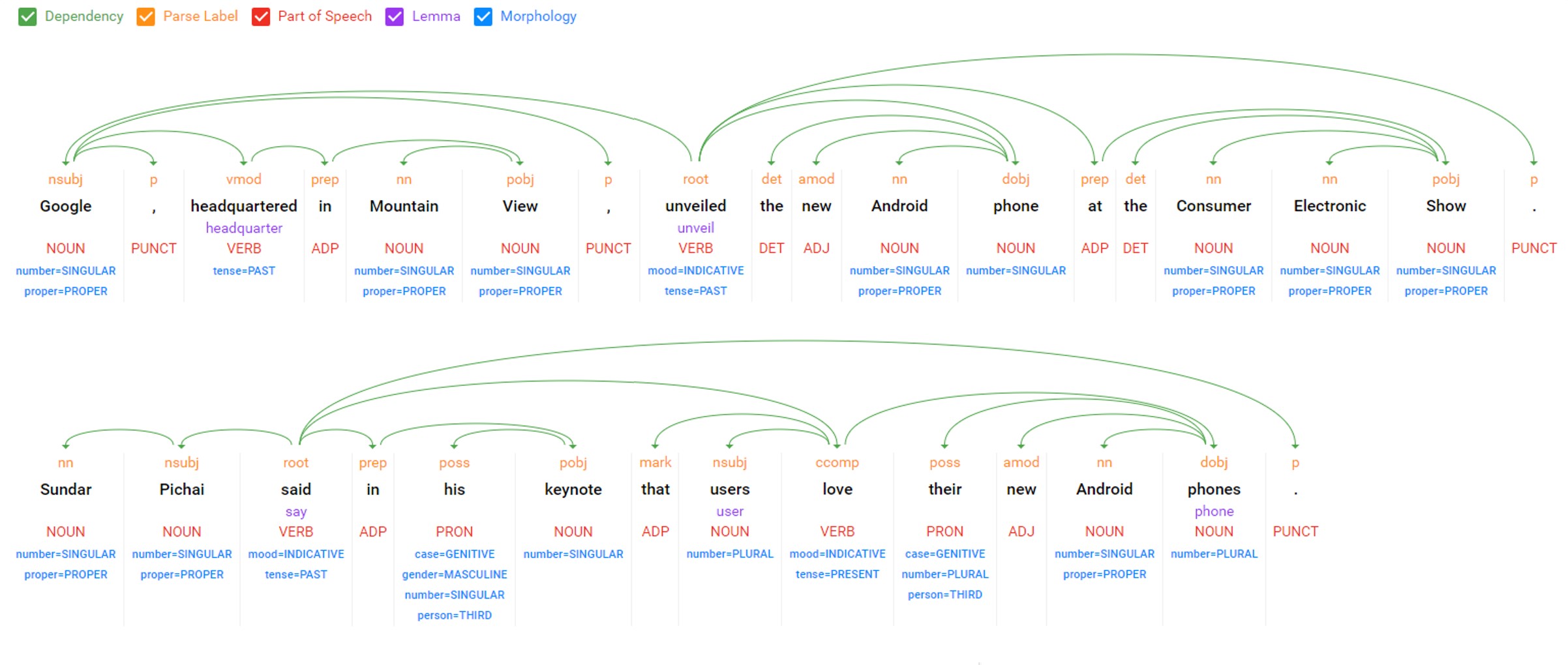
- Advantages – Easy to create patterns, can be done by business users, does not require programming, easy to debug and fix, runs fast, matches directly to desired outputs
- Disadvantages – Requires on-going pattern maintenance, cannot match on newly invented constructs
- Advantages – patterns are created automatically, built-in statistical trade-offs
- Disadvantages – requires generating extensive training data (1000’s of examples), will need to be periodically retrained for best accuracy, cannot match on newly invented constructs, harder to debug

Note that these patterns may be entered manually, or they may be derived statistically (and weighted statistically) using training data or inferred using text mining and machine learning.
Development frameworks for NLP:
- Open NLP – has many components; is complex to work with; parsing is done with the “top down” approach
- UIMA – has many components and statistical annotation; tends to require a lot of programming; lends itself to a bottoms-up / statistical approach, but not easily implemented
- GATE – configurable bottoms-up approach; is much easier to work with, but configurations must still be created by programmers (not business users)
Service frameworks for NLP:
- IBM Cognitive – statistical approach based on training data
- Google Cloud Natural Language API – top-down full-sentence diagramming system
- Amazon Lex – geared more towards human-interactive (human in the loop) conversations
Some tricky things to watch out for:
- Co-reference resolution - sentences often refer to previous objects. This can include the references below. In all of these cases, the desired data refers to a previous, more explicitly defined entity. To achieve the highest possible coverage, your software will need to identify these back references and resolve them.
- Pronoun reference: “She is 49 years old.”
- Partial reference: “Linda Nelson is a top accountant working in Hawaii. Linda is 49 years old.”
- Implied container reference: “The state of Maryland is a place of history. The capital, Annapolis, was founded in 1649.”
- Handling lists and repeated items
- For example: “The largest cities in Maryland are Baltimore, Columbia, Germantown, Silver Spring, and Waldorf.”
- Such lists often break NLP algorithms and may require special handling which exists outside the standard structures.
- Handling embedded structures such as tables, markup, bulleted lists, headings, etc.
- Note that structure elements can also play havoc with NLP technologies.
- Make sure that NLP does not match sentences and patterns across structural boundaries. For example, from one bullet point and into the next.
- Make sure that markup does not break NLP analysis where it shouldn’t. For example, embedded emphasis should not cause undue problems.
STEP 6: Maintain Provenance / Traceability
At some point, someone will point to a piece of data produced by your system and say: “That looks wrong. Where did it come from?”
Acquiring content from the Internet and then extracting information from that content will likely involve many steps and a large number of computational stages. It is important to provide traceability (provenance) for all outputs so that you can carefully trace back through the system to identify exactly how that information came to be.
This usually involves:
- Save the original web pages which provided the content
- Save the start and end character positions of all blocks of text extracted from the web page
- Save the start and end character positions for all entities, plus the entity ID and entity type ID matched
- Save the start and end character positions for all patterns matched, plus the pattern ID and sub-pattern IDs (for nested or recursive patterns)
- Identify other cleansing or normalization functions applied / used by all content
By saving this information throughout the process, you can trace back from the outputs all the way back to the original web page or file which provided the content that was processed. This will allow you to answer the question “Where did this come from?” with perfect accuracy, and will also make it possible to do quality analysis at every step.
STEP 7: Human-Aided Processes
Note that content understanding can never be done without some human intervention somewhere:
- For creating or cleansing or choosing lists of known entities
- For evaluating output accuracy
- To discover new patterns
- To evaluate and correct outputs
- To create training data
Many of these processes can be mind-numbingly repetitive. In a large-scale system, you will need to consider the human element and build that into your NLP system architecture.
Some options include:
- Creating user interfaces to simplify and guide the human evaluation process, for example, allowing users to easily tag entities in content using a WYSIWYG tool and providing easily editable lists to review (with sortable statistics and easy character searching)
- Leveraging crowd-sourcing to scale out human-aided processes, for example, using CrowdFlower
- Finding ways to incorporate human review / human-in-the-loop as part of the standard business process, for example, pre-filling out a form using extracted understanding and having the employee review it before clicking “save” and uploading new content
NLP methods and applications
How computers make sense of textual dataNLP and text analytics
- Investigative discovery. Identify patterns and clues in emails or written reports to help detect and solve crimes.
- Subject-matter expertise. Classify content into meaningful topics so you can take action and discover trends.
- Social media analytics. Track awareness and sentiment about specific topics and identify key influencers.
- Have you ever looked at the emails in your spam folder and noticed similarities in the subject lines? You’re seeing Bayesian spam filtering, a statistical NLP technique that compares the words in spam to valid emails to identify junk mail.
- Have you ever missed a phone call and read the automatic transcript of the voicemail in your email inbox or smartphone app? That’s speech-to-text conversion, an NLP capability.
- Have you ever navigated a website by using its built-in search bar, or by selecting suggested topic, entity or category tags? Then you’ve used NLP methods for search, topic modeling, entity extraction and content categorization.
The evolution of NLP toward NLU has a lot of important implications for businesses and consumers alike. Imagine the power of an algorithm that can understand the meaning and nuance of human language in many contexts, from medicine to law to the classroom. As the volumes of unstructured information continue to grow exponentially, we will benefit from computers’ tireless ability to help us make sense of it all.
Future of Natural Language Processing
A 2017 Tractica report on the natural language processing (NLP) market estimates the total NLP software, hardware, and services market opportunity to be around $22.3 billion by 2025. The report also forecasts that NLP software solutions leveraging AI will see a market growth from $136 million in 2016 to $5.4 billion by 2025.
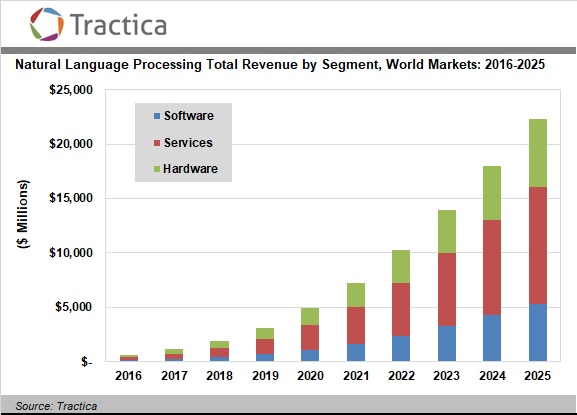
Here are some of the future possibilities of NLP:
Healthcare
It is not uncommon for medical personnel to pore over various sources trying to find the best viable treatment methods for a complex medical condition, variations of certain diseases, complicated surgeries, and so on.
Information discovery and retrieval: A plausible application of NLP technologies here could be real-time information discovery and retrieval. That is, the healthcare AI solution will be able to understand the medical terminology and retrieve relevant medical information from the most reputable sources in real time. “This does not mean that the AI is inventing treatments,but enabling easy access to the right data at the right time.”
Diagnostic assistance: Another near-term and practical NLP application in healthcare, is diagnostic assistance. For example, a radiologist looking at a report could take the help of AI to pull up diagnostic guidelines from the American College of Radiology database. The AI system will periodically ask the medical examiner clarifying questions to make appropriate, relevant diagnostic suggestions.
Virtual healthcare assistant: These NLP capabilities could be extended further to create an intelligent healthcare AI assistant. This AI medical assistant will understand conversations using NLU models enabled with medical vocabulary. Trained on medical terminology and data, it would be able to listen and interpret conversations between a doctor and a patient (with consent) so that it can transcribe, summarize the conversation as notes for future reference, and even create structured draft reports (which could take hours to manually create). This would minimize the manual labor of healthcare personnel so they can invest their time in catering to patients.
Image classification and report generation: Extending existing NLP technologies such as automated image captioning to healthcare AI systems would be extremely useful in report generation from images or X-rays. The AI would be able to understand medical images and electronic health records. It could then “post-process” them using deep learning based analytics running in real time and offer prognosis or predict certain medical conditions, such as the potential risk of renal failure.
Personal Virtual Assistance
Current virtual AI assistants (such as Siri, Alexa, Echo, etc.) understand and respond to vocal commands in a sequence. That is, they execute one command at a time. However, to take on more complex tasks, they have to be able to converse, much like a human.
Real-time vocal communication is riddled with imperfections such as slang, abbreviations, fillers, mispronunciations, and so on, which can be understood by a human listener sharing the same language as the speaker. In the future, this NLP capability of understanding the imperfections of real-time vocal communication will be extended to the conversational AI solutions.
For example, to plan a series of events, a user will be able to converse with the AI like he would with a human assistant. Vlad gives a common example of a colloquial command:
“Hey, I want to go out to dinner with my friend after my last meeting on Thursday. Take care of it.”The AI would be able to comprehend the command, divide the complex task into simpler subtasks and execute them. To achieve this, the virtual assistant would have to consult the calendars of both the user and the friend to determine a common time when they are both available, know the end time of the last meeting on the specified day or date, check the availability of restaurants, present the user with the list of nearby restaurants, etc. The user would be able to review the AI’s suggestions and amend it, after which the AI can create the event in the user’s calendar.
Automotive
The automotive industry, particularly cars, as a “preeminent AI platform.” Automotive is a fast-moving consumer tech area, and car OEMs are evolving fast. Cars will be increasingly used as autonomous robots whose transportational capabilities could be augmented with other onboard computational capabilities and sensors. 
Another example that could make his vision a possibility in the future is that of a car AI being able to independently communicate with the driver’s home AI systems to delegate certain commands it can’t carry out by itself.
For instance, the car assistant should understand the user’s command to open the garage door on arrival. The assistant should also “know” that it is not directly equipped to carry out this command. Therefore, it would identify and interact with the appropriate AI software that can open the garage door. In fact, Amazon recently announced that BMW will integrate Alexa into their vehicles in 2018, which will give the drivers access to their Alexa from their cars through voice commands.
Customer Service
In the customer service field, advanced NLP technologies could be used to analyze voice calls and emails in terms of customer happiness quotient, prevalent problem topics, sentiment analysis, etc.
For example, NLP could be used to extract insights from the tone and words of customers in textual messages and voice calls that can be used to analyze the frequency of the problem topic at hand and which features and services receive the most complaints, etc. using clustering in NLP for broad information search, businesses can coax out patterns in the problem topics, tracking the biggest concerns among customers, etc.
Further, these technologies could be used to provide customer service agents with a readily available script that is relevant to the customer’s problem. The system could simply “listen” to the topics being addressed and mesh that information with the customer’s record.This means that customer agents needn’t spend time on putting callers on hold while they consult their supervisors or use traditional intraweb search to address customers concerns.
Concluding Thoughts
Future vision of NLP applications conjures an AI world that is an ecosystem unto itself with a vast improvement in the interoperability between different AI systems. This means, a user will be able to communicate or interact with his/her home AI system right from their vehicle or workspace. Many such voice-controlled NLP systems have already made their way into the market, including apps that help control smart machines like washing machines, thermostats, ovens, pet monitoring systems, etc., from a phone or tablet. Below are some of the insights:
Human-like virtual assistants: Virtual assistants will become better at understanding and responding to complex and long-form natural language requests, which use conversational language, in real time. These assistants will be able to converse more like humans, take notes during dictation, analyze complex requests and execute tasks in a single context, suggest important improvements to business documents, and more.
Information retrieval from unstructured data: NLP solutions will increasingly gather useful intelligence from unstructured data such as long-form texts, videos, audios, etc. They will be able to analyze the tone, voice, choice of words, and sentiments of the data to gather analytics, such as gauging customer satisfaction or identifying problem areas. This could be extremely useful with call transcripts and customer responses via email, social media, etc, which use free-form language with abbreviations and slangs. This ability will also be put to good use in gathering intelligence from textual business reports, legal documents, medical reports, etc.
Smart search: Users will be able to search via voice commands rather than typing or using keywords. NLP systems will increasingly use image and object classification methods to help users search using images. For example, a user will be able to take a picture of a vehicle they like and use it to identify its make and model so they can buy similar vehicles online.
Sources: History of NLP - https://en.wikipedia.org/wiki/Natural_language_processing Natural Language Processing Steps - https://www.researchgate.net/figure/Natural-Language-Processing-steps_fig1_31170516 Researchgate - https://www.researchgate.net/figure/General-scheme-of-natural-language-processing-algorithm_fig3_238439138
Comments (11 Comments)





























Leave a Reply