



Share with:
Big data is a term used to define enormous amounts of data. Huge sets of data measured in petabytes or exabytes used for analyzing and improving the living world is defined as Big Data. The size of data to be considered as Big Data is around 6 petabytes. Big Data calls for applications to tag, model, store, analyze and process to obtain some useful information.
BigData and Architecture?System Architecture refers to the organization of a body of components and the interactions between them. The architecture of the system is important since we have a huge development in technology today. Applications are getting larger and there is a need for a lot of data integration. A good architecture helps in providing better communication between the developers and customers involved. It represents an early design decision of the system before development.
Big Data is defined based on the three V’s
- Volume: Size of the data.
- Velocity: The speed with which the data is streamed requires it to be processed in an appropriate manner.
- Variety: Numerous sources of data is available which may be structured, unstructured or both.
Each phase has important criteria that must be met and real-time performance needs. Hence, testing of Big Data applications and the tools used are tremendously important, and testing must be performed properly. To develop trustworthy applications and to prove the correctness of the information an intensive testing approach must be engaged. The test environment should facilitate large storage spaces, clusters, and distributed nodes and with hardware which can process data in a minimal time.
Testing Big Data:When testing Big Data the foremost area to focus on in the architecture of the systems. A poorly designed system architecture will introduce many problems for Big Data applications related to performance and functionality. Big Data testing involves validation of structured and unstructured data values, having an optimal test environment, dealing with non-relational databases, and performing nonfunctional testing. Failure of any of the above will result in poor quality of data and a high cost of re-testing the data. Architecture testing refers to the testing of the system design which refers to a plan of how it is to be implemented. In a test-driven development unit testing, acceptance testing, and integration testing are performed for architectural testing of a system. The architectural quality involves the internal qualities of the system and provides quality code management. Regression testing techniques are used at the architectural level to reduce the cost of retesting the system after future modifications are made. Architectural testing must be guided by the definition of the system architecture, which is done by using specification languages and analysis techniques.
Big Data Architecture:
One of the well known and widely implemented architectures in Big Data is the MapReduce. MapReduce is an architectural framework for processing huge amounts of data. It was initially proposed in 2004 by Google which is based on the No-SQL drift. It was implemented in tools such as Mars, Phoenix and Hadoop (which is most popular in the present day). Hadoop MapReduce is based on the shared-nothing architecture which doesn't allow sharing of altering data and stance challenges for some of its algorithms. It can run applications on parallel computing clusters by distributing the large amounts of data over the network. The main emphasis of the architecture is to distribute, parallelize and balance the data load in a system. Any library or tool which is built on Map reduce architecture is based on key-value pairs. It will have three major parts a Master, map and a reduce function.
The image table gives us an idea of how the functions operate and clustering is handled in MapReduce.
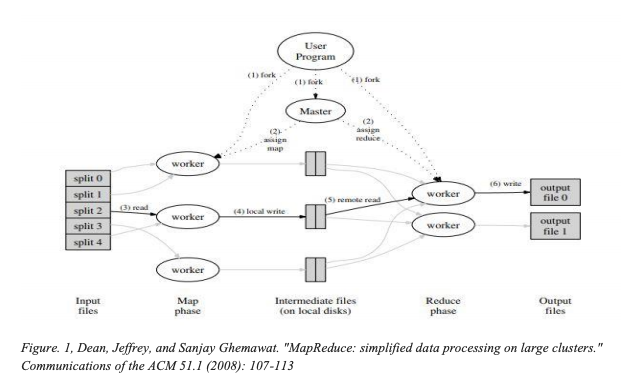
MapReduce is intended to withstand faults as it is a data-intensive application architecture. It is a good choice as it
- Can process petabytes of data by handling failures.
- Supports Data recovery.
- Does Parallel and distributed information processing
When it comes to testing any system Unit testing is the first and foremost. In addition, MapReduce systems need a tester to replicate the system behavior in all the Mapping, Combining and Reducing stages. Further, A MapReduce system calls for dynamic testing and distributed testing. It is possible to identify the performance, node failures, and network latency issues only during an active execution. Distributed testing can be performed as the testers would be assigned individual test cases which restricts fault injections in any state. Due to the size of data it handles, MapReduce applications potentially pose failures, thus increasing the weight on the testers. The testing team must be much aware of the processes, frameworks, and notions introduced. They should also work in collaboration with the Data and system architects. A need for enormous amounts of test data arises as the number of faults found may vary proportionally with size. Test data creation is moreover firmly identified with execution issues. Test cases and the test data must be created in accordance with the architecture, design, and workflow. Equivalence class partitioning can be used to partition the test data into meaningful clusters to verify the functionality and performance of the application. Boundary value analysis is another testing technique which focuses on the equivalence class boundaries. It is evident that testing the data around boundaries yields some good results.
Challenges of Testing:The major issue while testing Big Data is having to deal with the unstructured or semistructured data because the traditional relational databases deal with structured data values. There are innumerable challenges handling large unstructured real-time data and just to understand the correlation with data between then and now makes Big Data testing an absolute nightmare. The test cases and test data with different permutations and combination are of humongous exponential power. A manual testing method would be tedious, so some type of automation test must be implemented. When testing, test data must be stored on the Big Data platform and the test environment must meet the standard of the source network to handle real-time data during testing. Big Data testing is always influenced by the below factors
Precision in integration
Data is collected from a wide variety of sources and integrated at some point, for the architecture tools to produce an efficient output the integration should be performed instantly and readily available.
Data collection and deployment
In a real-time environment where the data changes from time to time, data collection and deployment is always a challenge.
Data quality
Feeding applications data in the right form and factor is essential for it to be processed and visualized in an efficient way, else the decision-making capabilities of the application will be affected. Scalability The applications must be scalable enough with the changing data to handle huge workloads based on the business expansions.
Failures
The data is distributed over nodes and clusters over a network in Big Data processing tools such as Hadoop. Failure to any node or a network would result in forfeiting consequence for companies.
Limitations & Future Trends
The major limitation about current testing methods is that they are done on stationary data flow while Big Data testing must be performed in the continuous data flow. Process architectures are built around centralized data, but Big Data architectures are designed for distributed data. In the former data types are static, but dynamic with Big Data. The current need is to test at each stage with real-time data, to achieve this we need to be test-driven development and quality on all levels. Now we have the test data completeness, data values, how relevant is the data, sentiment, and behavior of unstructured real-time data. Multiple copies of Big Data are other challenges that must be handled in an environment where the efficiency of query executing is poor.
Source: Eurostar Software Testing Conference Conclusion:Testing both functional and non-functional requirements (such as performance, quality, and correctness of data) is required for any Big Data application to perform at its best. Though a system is tested for functional and non-functional requirements the test results are completely domain dependent and vary from each application domain. In the future, we focus to examine the correlation between the type of faults and generalize across all domains of Big Data.
About the Author: Ananth Iyer The writer of this article is a Ph.D. Student & Graduate Teaching Assistant for the Department Of Computer Science at The University of North Dakota. Sources:[1] Zhengyi jin, “a software architecture-based testing technique”, dissertation submitted to the graduate faculty of George Mason University, 2000. [2] Hassan Reza, Suhas Lande,” Model-Based Testing Using Software Architecture”, Seventh International Conference on Information Technology: New Generations, 2010. [3] Juan Jin, Fei Xue, “Rethinking Software Testing Based on Software Architecture”, Seventh International Conference on Semantics, Knowledge, and Grids, 2011. [4] Antonia Bertolino, Paola Inverardi, Henry Muccini, Andrea Rosetti, “An Approach to Integration Testing Based on Architectural Descriptions”, Universita’ di L’Aquila, Dipartimento di Matematica Pura ed Applicata. [5] Ashlesha S. Nagdive, Dr. R. M. Tugnayat, Manish P. Tembhurkar, “Overview on Performance Testing Approach in Big Data”, International Journal of Advanced Research in Computer Science, 2014. [6] Muthuraman Thangaraj, Subramanian Anuradha, “State of the art in Testing for Big Data”, IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), 2015. [7] Swati Panwar, “How to Test Big Data Systems”, June 9, 2016. [8] Riya Rose, “Big Data Testing – How to Overcome Quality Challenges”, 2017. [9] Garg, Naveen, Sanjay Singla, and Surender Jangra. "Challenges and techniques for testing of Big Data." Procedia Computer Science 85 (2016): 940-948. [10] Khezr, Seyed Nima, and Nima Jafari Navimipour. "MapReduce and its applications, challenges, and architecture: a comprehensive review and directions for future research." Journal of Grid Computing 15.3 (2017): 295-321. [11] Aarnio, Tomi. "Parallel data processing with MapReduce." TKK T-110.5190, Seminar on Internetworking. 2009. [12] Tinetti, Fernando G., et al. "Hadoop Scalability and Performance Testing in H
Comments (4 Comments)























Leave a Reply