



A database is a collection of information, organized in tables which allow easy access to the user. Data in a database is available in rows and columns with an index to improve the accessibility. A database can be found and is also necessary for almost every day to day tasks like sales, marketing, education and many more. In recent days Database is considered as the heart of any transaction processing system.
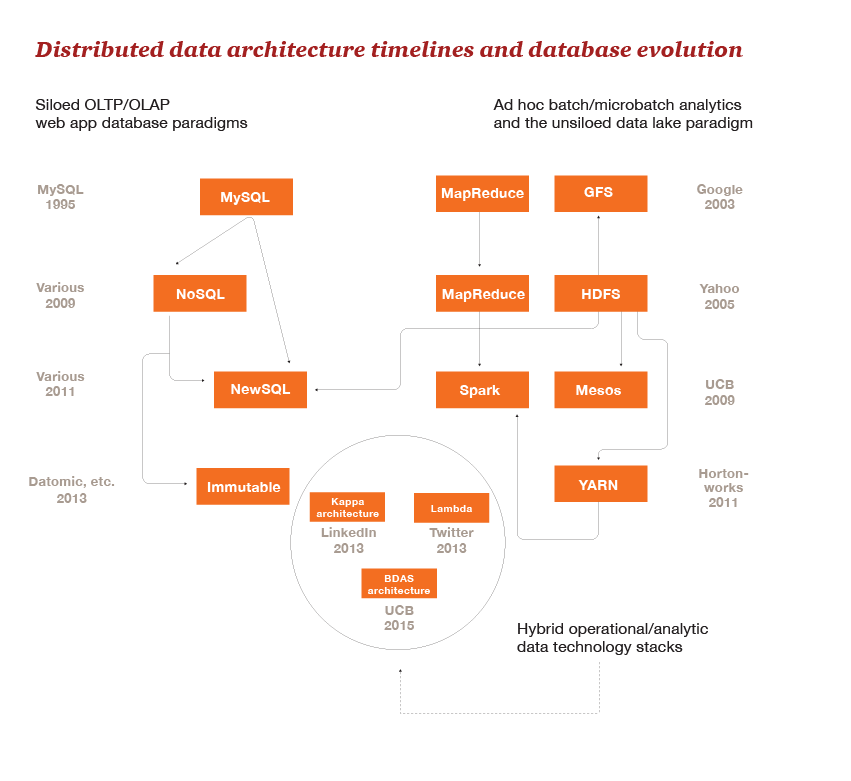
History:Databases have been evolving from the early 1960's which started with hierarchical databases, network databases, relational databases, NoSQL Databases and currently cloud databases.
- 1960’s – 70’s - Hierarchical and network databases evolved.
- 1990’s – Object-oriented databases, OLAP (Online Analytical Processing)
- 2000’s – NoSQL, BigData graphs and many more.
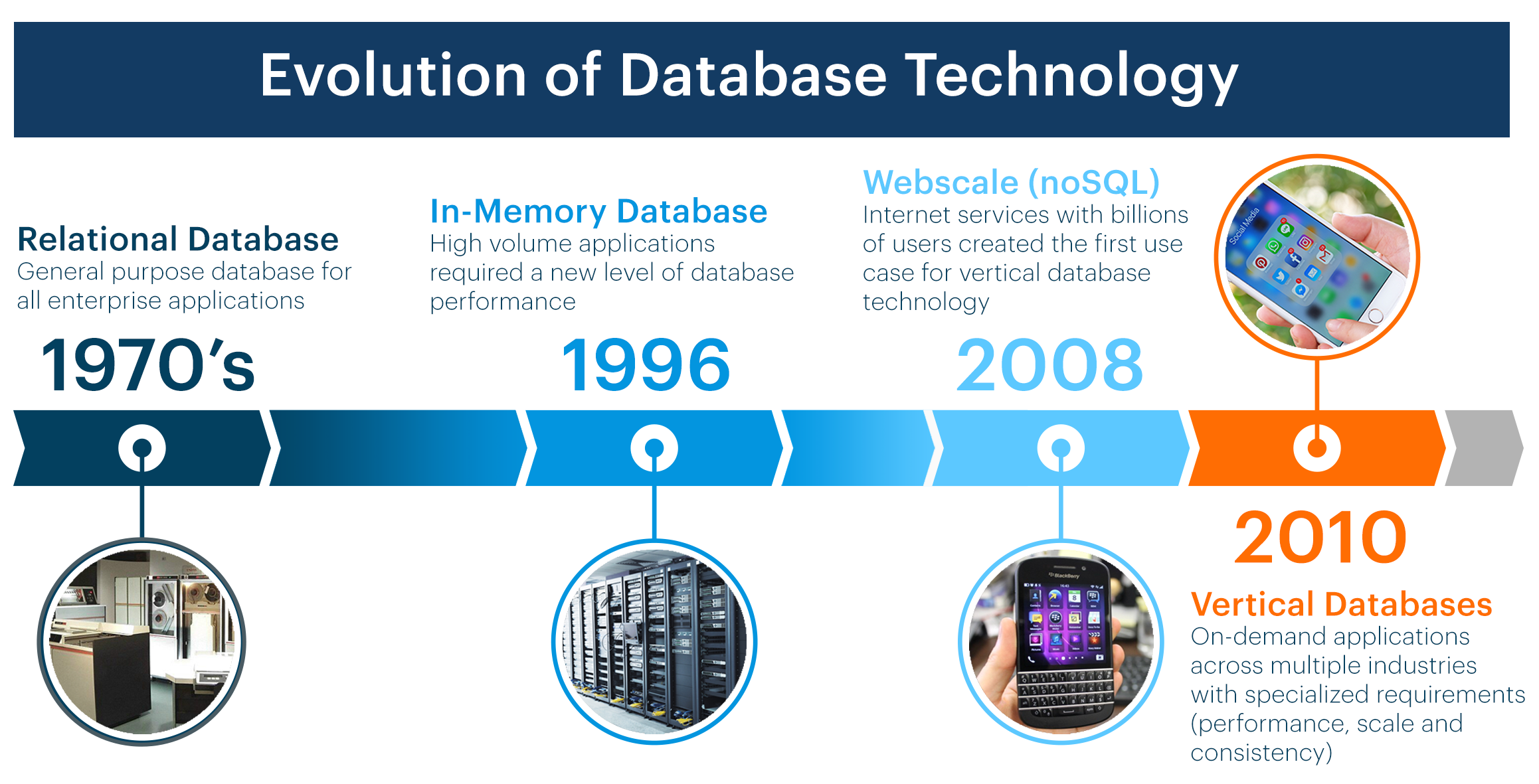
Types of Database:
Databases are also classified into other types based on the approach involved. Some of the database types evolved between 1995 to 2015 are listed below:
Relational Database:
It was invented by E.F. Codd in the year 1970 at IBM. It is a traditional database based on the tables through which data can be accessed and manipulated. The tables in the relational database cannot be empty i.e. there should be at least one data item in each row corresponding to a column. SQL or structured query language is used to interact with a relational database.
MySQL is an example for Relational database.
Distributed database:
A database which has parts of data stored in multiple locations and the processing is scattered among these locations and connected through a network. They may be all of the same type or multiple types of hardware and software over different locations, but their collective purpose is to serve the systems requests.
Oracle server is an example for Distributed database.
Cloud database:
It is a virtual database which is hosted on a public or private cloud platform. Its major advantage over all other databases is it doesn’t require all the huge storage and server hardware as the service is hosted over a secure network. Other advantages include high scalability and availability.
Microsoft Azure is an example of a cloud database.
NoSQL Database:
The database which helps organizations analyze enormous amounts of unstructured data is known as NoSQL databases. The main purpose of its origin is that it overcomes the performance issues of a relational database. This kind of databases process information available on multiple virtual servers around the globe.
Hybrid Database:
A hybrid database is a database management system that is a balanced database management system which offers high performance data processing in main memory with the vast storage capabilities of physical disk.
A hybrid database has both in-memory database features and on-disk database features in a single unified engine. As a result, data can be stored and manipulated in main memory alone, on disk alone or a combination of both. The integrated combination of both database types allows for unrivaled flexibility and robust functionality.
To fully understand why, it is important to understand the Pro's and Con's of in-memory and disk-resident databases.
In-memory databases are almost always significantly faster than any disk-resident database. In addition, the fact that data resides directly in RAM means that response times and latency are extremely low (microsecond scale). However, the downside is that RAM is significantly more expensive than traditional hard disks, and also has smaller storage capacity.
In contrast, disk-resident databases generally have fairly poor performance. This is because disk I/O is very expensive, and the architecture of the database often spends a lot of CPU resources optimizing disk access patterns. However, disk-resident databases have immense storage capacity and this storage is fairly cheap.
This is why a hybrid engine is so attractive. By combining an in-memory database and a disk-resident database into one solution, you effectively get all the benefits and eliminate all the disadvantages. Need high performance? Use memory tables. Need lots of storage? Use disk tables.
Future Trends of Database Technology
Converged Database
Convinced that we can “have it all” within a single database offering. For instance, there is no architectural reason why a database system should not be able to offer a consistency model that includes at one end strict multi-record ACID transactions and at the other end an eventual consistency style model.
An ideal Converged database architecture would:
- Support a tunable consistency model which allows for strict RDBMS-style ACID transactions, Dynamo-style eventual consistency, or any point between.
- Provide support for an extensible but relational compatible schema by allowing data to be represented broadly by a relational model, but also allowing for application-extensible schemas, possibly by supporting embedded JSON data types.
- Such a database would support multiple languages and APIs. SQL appears destined to remain the primary database access language, but should be supplemented by graph languages such as Cypher, document-style queries based on REST and the ability to express processing in MapReduce or other Directed Acyclic Graph algorithms.
- An underlying pluggable data storage model should allow the physical storage of data to be based on row oriented or columnar storage is appropriate and on disk as B-trees, Log Structured Merge trees or other optimal storage structures.
- Support a range of distributed availability and consistency characteristics. In particular, the application should be able to determine the level of availability and consistency that is supported in the event of a network partition and be able to fine tune the replication of data across a potentially globally distributed system.
Disruptive Database Technologies
Disruptive technologies emerge which create discontinuities that cannot be extrapolated and cannot always be fully anticipated. It’s possible that a disruptive new database technology is imminent, but it’s just as likely that the big changes in database technology that have occurred within the last decade represent as much change as we can easily accept. There are a few computing technology trends which extend beyond database architecture and which may impinge heavily on the databases of the future.
Universal Memory
Since the dawn of digital databases, there has been a strong conflict between the economics of speed and the economics of storage. The medium that offers the greatest economies for storing large amounts of data (magnetic disk, tape) offers the slowest times and therefore the worst economics for throughput and latency. Conversely, the medium that offer the lowest latency and the highest throughput (memory, SSD) is the most expensive per unit of storage.
However, should a technology arise that simultaneously provides acceptable economics for mass storage and latency then we might see an almost immediate shift in database architectures. Such a universal memory would provide access speeds equivalent to RAM together with the durability, persistence and storage economics of disk.
Most technologists believe that it will be some years before such a disruptive storage technology arises though, given the heavy and continuing investment, it seems likely that we will eventually create a persistent, fast, and economical storage medium that can meet the needs of all database workloads. When this happens, many of the database architectures we see today will have lost a key part of their rationale. For instance, the difference between Spark and Hadoop would become minimal if persistent storage (aka. disk) was as fast as memory.
Blockchain
Blockchain is the distributed ledger that underlies the Bitcoin cryptocurrency. Blockchain arguably represent a new sort of shared distributed  database. Similar to systems based on the Dynamo model, the data in the block chain is distributed redundantly across a large number of hosts. However, the Blockchain represents a complete paradigm shift in how permissions are managed within the database. In an existing database system, the database owner has absolute control over the data held in the database. However, in a Blockchain system, ownership is maintained by the creator of the data.
database. Similar to systems based on the Dynamo model, the data in the block chain is distributed redundantly across a large number of hosts. However, the Blockchain represents a complete paradigm shift in how permissions are managed within the database. In an existing database system, the database owner has absolute control over the data held in the database. However, in a Blockchain system, ownership is maintained by the creator of the data.
Consider a database that maintains a social network such as Facebook: Although the application is programmed to allow only you to modify your own posts or personal details, the reality is that the Facebook company actually has total control over your online data. They can – if they wish – remove your posts, censor your posts, or even modify your posts if they really wanted to. In a Blockchain-based database, you would retain total ownership of your posts and it would be impossible for any other entity to modify them.
Quantum Computing

Using Quantum effects to create a new type of computer was popularized by physicist Richard Feynman back in the 1980s. The essential concept is to use subatomic particle behavior as the building blocks of computing.
Quantum computers promise to provide a mechanism for leapfrogging the limitations of silicon based technology and raises the possibility of completely revolutionizing cryptography. The promise that quantum computers could break existing private/public key encryption schemes seems increasingly likely, while quantum key transmission already provides a tamper-proof mechanism for transmitting certificates over distances within a few hundreds of kilometers.
If quantum computing realizes its theoretical potential it would have enormous impact on all areas of computing – databases included. There are also some database–specific quantum computing proposals:
- Quantum transactions: Inspired by the concept of superimposition, it’s proposed that data in database could be kept in a “quantum” state, effectively representing multiple possible outcomes.
- Quantum search: A quantum computer could potentially provide an acceleration of search performance over a traditional database. A quantum computer could more rapidly execute a full table scan and find matching rows for a complex non-indexed search term. The improvement is unlikely to be decisive when traditional disk access is the limiting factor, but for in-memory databases it’s possible that quantum database search may become a practical innovation.

- Quantum Query Language: The fundamental unit of processing in a classical (e.g., non-quantum) computer is the bit - which represents one of two binary states. In a quantum computer, the fundamental unit of processing is the qubit which represents the superimposition of all possible states of a bit. To persistently store the information from a quantum computer would require a truly quantum-enabled database which was capable executing logical operations using qubit logic rather than Boolean bit-logic. Operations on such a database would require a new language which could represent quantum operations instead of the relational predicates of SQL. Such a language has been proposed: Quantum Query Language (QQL).

Sources:
https://cacm.acm.org/news/227272-the-search-for-universal-memory/fulltext
Comments (9 Comments)






























Leave a Reply