


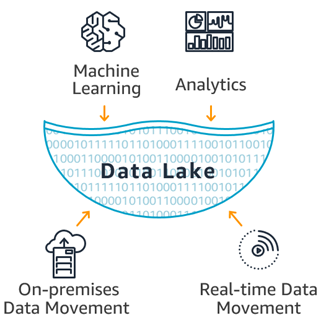

Organizations that successfully generate business value from their data, outperform their peers. An Aberdeen survey saw organizations who implemented a Data Lake outperforming similar companies by 9% in organic revenue growth. These leaders were able to do new types of analytics like machine learning over new sources like log files, data from click-streams, social media, and internet connected devices stored in the data lake. This helped them to identify, and act upon opportunities for business growth faster by attracting and retaining customers, boosting productivity, proactively maintaining devices, and making informed decisions.
 Organizations that successfully generate business value from their data, outperform their peers. An
Organizations that successfully generate business value from their data, outperform their peers. An ABOUT DATA LAKE
Data Lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics – from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
HISTORY
James Dixon, then chief technology officer at Pentaho, allegedly coined the term to contrast it with data mart, which is a smaller repository of interesting attributes derived from raw data. In promoting data lakes, he argued that data marts have several inherent problems, such as information siloing. PricewaterhouseCoopers said that data lakes could “put an end to data silos. In their study on data lakes they noted that enterprises were “starting to extract and place data for analytics into a single, Hadoop-based repository.”
As organizations are building Data Lakes and an Analytics platform, they need to consider a number of key capabilities including and develop the architecture:DATA LAKE SOLUTION - ESSENTIALS & ARCHITECTURE
DATA LAKE - ESSENTIALS
Data movement
Securely store, and catalog data
Analytics
Machine Learning
 Data Lakes will allow organizations to generate different types of insights including reporting on historical data, and doing machine learning where models are built to forecast likely outcomes, and suggest a range of prescribed actions to achieve the optimal result.
Data Lakes will allow organizations to generate different types of insights including reporting on historical data, and doing machine learning where models are built to forecast likely outcomes, and suggest a range of prescribed actions to achieve the optimal result.
BUILDING THE ARCHITECTURE
Design Physical Storage
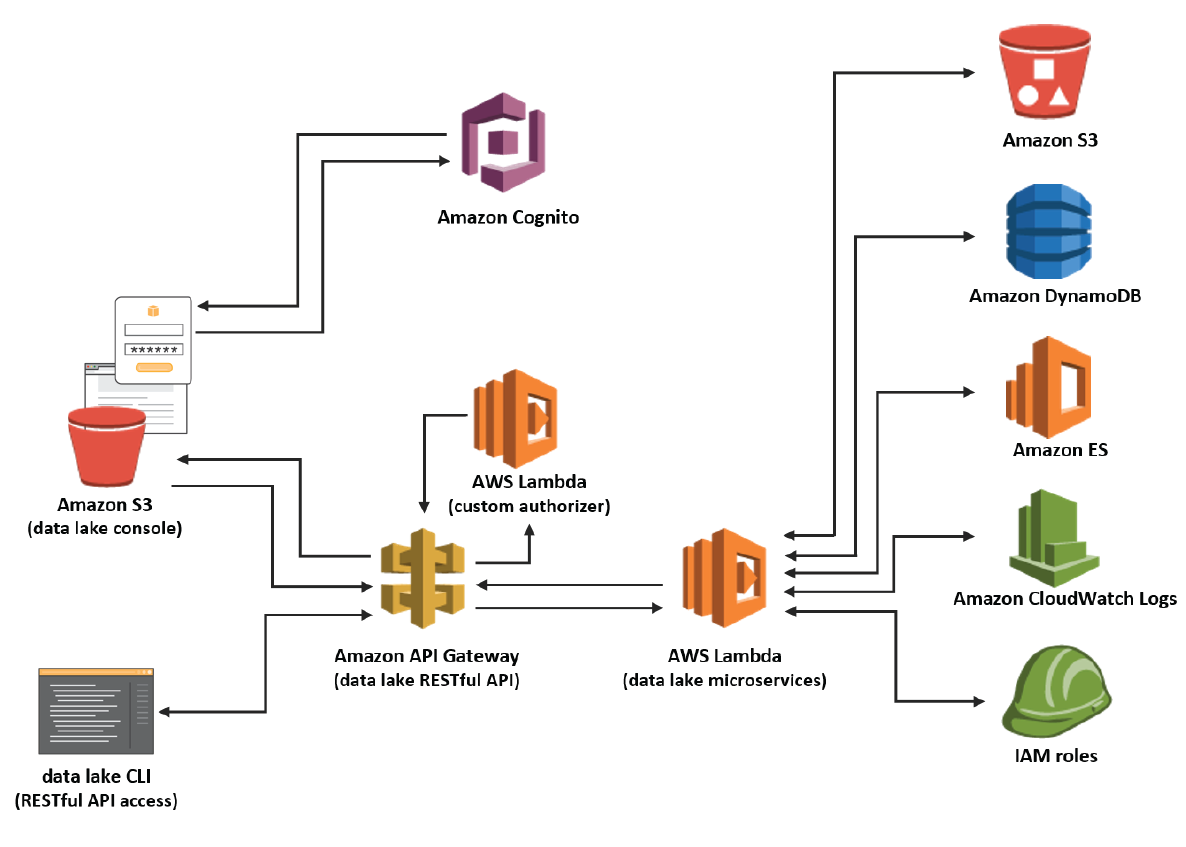 Design Physical Storage
Design Physical StorageThe foundation of any data lake design and implementation is physical storage. The core storage layer is used for the primary data assets. Typically it will contain raw and/or lightly processed data. The key considerations when evaluating technologies for cloud-based data lake storage are the following principles and requirements:
Exceptional scalability
Because an enterprise data lake is usually intended to be the centralized data store for an entire division or the company at large, it must be capable of significant scaling without running into fixed arbitrary capacity limits.
High durability
 As a primary repository of critical enterprise data, a very high durability of the core storage layer allows for excellent data robustness without resorting to extreme high-availability designs.
As a primary repository of critical enterprise data, a very high durability of the core storage layer allows for excellent data robustness without resorting to extreme high-availability designs.
Support for unstructured, semi-structured and structured data
One of the primary design considerations of a data lake is the capability to store data of all types in a single repository.
Independence from fixed schema
The ability to apply schema upon read, as needed for each consumption purpose, can only be accomplished if the underlying core storage layer does not dictate a fixed schema.
Separation from compute resources
The most significant philosophical and practical advantage of cloud-based data lakes as compared to “legacy” big data storage on Hadoop is the ability to decouple storage from compute, enabling independent scaling of each. Given the requirements, object-based stores have become the de facto choice for core data lake storage. AWS, Google and Azure all offer object storage technologies.
 The point of the core storage is to centralize data of all types, with little to no schema structure imposed upon it. However, a data lake will typically have additional “layers” on top of the core storage. This allows the retention of the raw data as essentially immutable, while the additional layers will usually have some structure added to them in order to assist in effective data consumption such as reporting and analysis.
The point of the core storage is to centralize data of all types, with little to no schema structure imposed upon it. However, a data lake will typically have additional “layers” on top of the core storage. This allows the retention of the raw data as essentially immutable, while the additional layers will usually have some structure added to them in order to assist in effective data consumption such as reporting and analysis.
A specific example of this would be the addition of a layer defined by a Hive metastore. In a layer such as this, the files in the object store are partitioned into “directories” and files clustered by Hive are arranged within to enhance access patterns depicted suffice to say that many additional layering approaches can be implemented depending on the desired consumption patterns.
Choose File Format
Introduction
 People coming from the traditional RDBMS world are often surprised at the extraordinary amount of control that we as architects of data lakes have over exactly how to store data. We, as opposed to an RDBMS storage engine, get to determine an array of elements such as file sizes, type of storage (row vs. columnar), degree of compression, indexing, schemas, and block sizes. These are related to the Hadoop-oriented ecosystem of tools commonly used for accessing data in a lake.
People coming from the traditional RDBMS world are often surprised at the extraordinary amount of control that we as architects of data lakes have over exactly how to store data. We, as opposed to an RDBMS storage engine, get to determine an array of elements such as file sizes, type of storage (row vs. columnar), degree of compression, indexing, schemas, and block sizes. These are related to the Hadoop-oriented ecosystem of tools commonly used for accessing data in a lake.
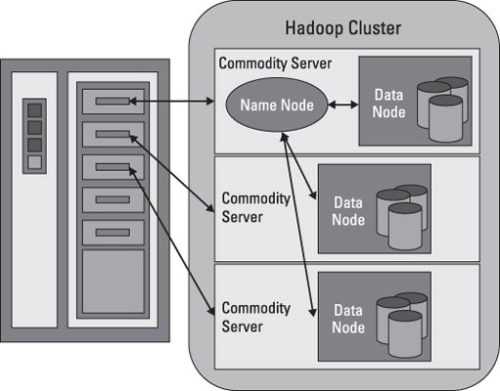
File Size
A small file is one which is significantly smaller than the Hadoop file system (HDFS) default block size, which is 128 MB. If we are storing small files, given the large data volumes of a data lake, we will end up with a very large number of files. Every file is represented as an object in the cluster’s name node’s memory, each of which occupies 150 bytes, as a rule of thumb. So 100 million files, each using a block, would use about 30 gigabytes of memory. The takeaway here is that Hadoop ecosystem tools are not optimized for efficiently accessing small files. They are primarily designed for large files, typically an even multiple of the block size.
Apache ORC
ORC is a prominent columnar file format designed for Hadoop workloads. The ability to read, decompress, and process only the values that are required for the current query is made possible by columnar file formatting. While there are multiple columnar formats available, many large Hadoop users have adopted ORC. For instance, Facebook uses ORC to save tens of petabytes in their data warehouse. They have also demonstrated that ORC is significantly faster than RC File or Parquet. Yahoo also uses ORC to store their production data and has likewise released some of their benchmark results.
Same Data, Multiple Formats
It is quite possible that one type of storage structure and file format is optimized for a particular workload but not quite suitable for another. In situations like these, given the low cost of storage, it is actually perfectly suitable to create multiple copies of the same data set with different underlying storage structures (partitions, folders) and file formats (e.g. ORC vs Parquet).
Design Security
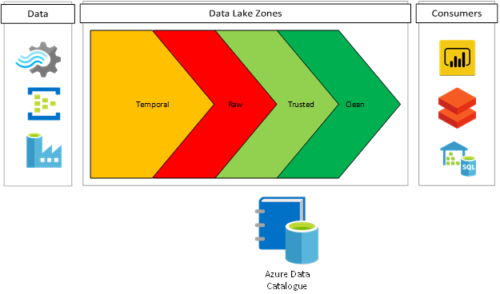 Like every cloud-based deployment, security for an enterprise data lake is a critical priority, and one that must be designed in from the beginning. Further, it can only be successful if the security for the data lake is deployed and managed within the framework of the enterprise’s overall security infrastructure and controls. Broadly, there are three primary domains of security relevant to a data lake deployment:
Like every cloud-based deployment, security for an enterprise data lake is a critical priority, and one that must be designed in from the beginning. Further, it can only be successful if the security for the data lake is deployed and managed within the framework of the enterprise’s overall security infrastructure and controls. Broadly, there are three primary domains of security relevant to a data lake deployment:
- Encryption
- Network Level Security
- Access Control
Encryption
Virtually every enterprise-level organization requires encryption for stored data, if not universally, at least for most classifications of data other than that which is publicly available. All leading cloud providers support encryption on their primary objects store technologies (such as AWS S3) either by default or as an option. Likewise, the technologies used for other storage layers such as derivative data stores for consumption typically offer encryption as well.
Encryption key management is also an important consideration, with requirements typically dictated by the enterprise’s overall security controls. Options include keys created and managed by the cloud provider, customer-generated keys managed by the cloud-provider, and keys fully created and managed by the customer on-premises.
The final related consideration is encryption in-transit. This covers data moving over the network between devices and services. In most situations, this is easily configured with either built-in options for each service, or by using standard TLS/SSL with associated certificates.
Network Level Security
Another important layer of security resides at the network level. Cloud-native constructs such as security groups, as well as traditional methods including network ACLs and CIDR block restrictions, all play a part in implementing a robust “defense-in-depth” strategy, by walling off large swaths of inappropriate access paths at the network level. This implementation should also be consistent with an enterprise’s overall security framework.
Access Control
This focuses on Authentication (who are you?) and Authorization (what are you allowed to do?). Virtually every enterprise will have standard authentication and user directory technologies already in place; Active Directory, for example. And every leading cloud provider supports methods for mapping the corporate identity infrastructure onto the permissions infrastructure of the cloud provider’s resources and services. While the plumbing involved can be complex, the roles associated with the access management infrastructure of the cloud provider are assumable by authenticated users, enabling fine-grained permissions control over authorized operations. The same is usually true for third-party products that run in the cloud such as reporting and BI tools. LDAP and/or Active Directory are typically supported for authentication, and the tools’ internal authorization and roles can be correlated with and driven by the authenticated users’ identities.
Establish Governance
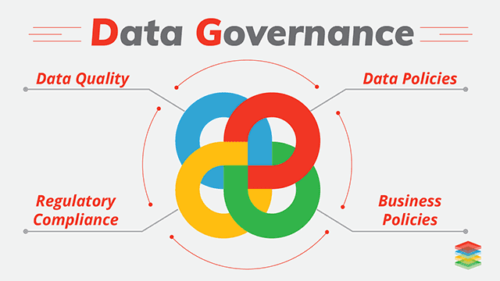 Typically, data governance refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. It relies on both business policies and technical practices. Similar to other described aspects of any cloud deployment, data governance for an enterprise data lake needs to be driven by, and consistent with, overarching practices and policies for the organization at large.
Typically, data governance refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. It relies on both business policies and technical practices. Similar to other described aspects of any cloud deployment, data governance for an enterprise data lake needs to be driven by, and consistent with, overarching practices and policies for the organization at large.
In traditional data warehouse infrastructures, control over database contents is typically aligned with the business data, and separated into silos by business unit or system function. However, in order to derive the benefits of centralizing an organization’s data, it correspondingly requires a centralized view of data governance.
Even if the enterprise is not fully mature in its data governance practices, it is critically important that at least a minimum set of controls is enforced such that data cannot enter the lake without important meta-data (“data about the data”) being defined and captured. While this depends in part on technical implementation of a metadata infrastructure as described in the earlier “Design Physical Storage” section, data governance also means that business processes determine the key metadata to be required. Similarly, data quality requirements related to concepts such as completeness, accuracy, consistency and standardization are in essence business policy decisions that must first be made, before baking the results of those decisions into the technical systems and processes that actually carry out these requirements.
The technologies used to implement data governance policies in a data lake implementation are typically not individual products or services. The better approach is to expect the need to embed the observance of data governance requirements into the entire data lake infrastructure and tools.
Enable Metadata Cataloging and Search
Key Considerations
 Any data lake design should incorporate a metadata storage strategy to enable the business users to be able to search, locate and learn about the datasets that are available in the lake. While traditional data warehousing stores a fixed and static set of meaningful data definitions and characteristics within the relational storage layer, data lake storage is intended to flexibly support the application of schema at read time. However, this means a separate storage layer is required to house cataloging metadata that represents technical and business meaning. While organizations sometimes simply accumulate contents in a data lake without a metadata layer, this is a recipe certain to create an unmanageable data swamp instead of a useful data lake. There are a wide range of approaches and solutions to ensure that appropriate metadata is created and maintained. Here are some important principles and patterns to keep in mind.
Any data lake design should incorporate a metadata storage strategy to enable the business users to be able to search, locate and learn about the datasets that are available in the lake. While traditional data warehousing stores a fixed and static set of meaningful data definitions and characteristics within the relational storage layer, data lake storage is intended to flexibly support the application of schema at read time. However, this means a separate storage layer is required to house cataloging metadata that represents technical and business meaning. While organizations sometimes simply accumulate contents in a data lake without a metadata layer, this is a recipe certain to create an unmanageable data swamp instead of a useful data lake. There are a wide range of approaches and solutions to ensure that appropriate metadata is created and maintained. Here are some important principles and patterns to keep in mind.
Enforce a metadata requirement
 The best way to ensure that appropriate metadata is created is to enforce its creation. Ensure that all methods through which data arrives in the core data lake layer enforce the metadata creation requirement, and that any new data ingestion routines must specify how the meta-data creation requirement will be enforced.
The best way to ensure that appropriate metadata is created is to enforce its creation. Ensure that all methods through which data arrives in the core data lake layer enforce the metadata creation requirement, and that any new data ingestion routines must specify how the meta-data creation requirement will be enforced.
Automate metadata creation
Like nearly everything on the cloud, automation is the key to consistency and accuracy. Wherever possible, design for automatic metadata creation extracted from source material.
Prioritize cloud-native solutions
Wherever possible, use cloud-native automation frameworks to capture, store and access metadata within your data lake. The core attributes that are typically cataloged for a data source are listed in Figure 3.
Access and Mine the Lake
Schema on Read
‘Schema on write’ is the tried and tested pattern of cleansing, transforming and adding a logical schema to the data before it is stored in a ‘structured’ relational database. However, as noted previously, data lakes are built on a completely different pattern of ‘schema on read’ that prevents the primary data store from being locked into a predetermined schema. Data is stored in a raw or only mildly processed format, and each analysis tool can impose on the dataset a business meaning that is appropriate to the analysis context. There are many benefits to this approach, including enabling various tools to access the data for various purposes.
Data Processing
Once you have the raw layer of immutable data in the lake, you will need to create multiple layers of processed data to enable various use cases in the organization. These are examples of the structured storage described earlier. Typical operations required to create these structured data stores will involve:
- Combining different datasets
- Denormalization
- Cleansing, deduplication, householding
- Deriving computed data fields
Apache Spark has become the leading tool of choice for processing the raw data layer to create various value-added, structured data layers.
Data Warehousing
For some specialized use cases (think high performance data warehouses), you may need to run SQL queries on petabytes of data and return complex analytical results very quickly. In those cases, you may need to ingest a portion of your data from your lake into a column store platform. Examples of tools to accomplish this would be Google BigQuery, Amazon Redshift or Azure SQL Data Warehouse.
Interactive Query and Reporting
There are still a large number of use cases that require support for regular SQL query tools to analyze these massive data stores. Apache Hive, Apache Presto, Amazon Athena, and Impala are all specifically developed to support these use cases by creating or utilizing a SQL-friendly schema on top of the raw data.
Data Exploration and Machine Learning
Finally, a category of users who are among the biggest beneficiaries of the data lake are your data scientists, who now can have access to enterprise-wide data, unfettered by various schemas, and who can then explore and mine the data for high-value business insights. Many data scientists tools are either based on or can work alongside Hadoop-based platforms that access the data lake.
Value of Data Lake
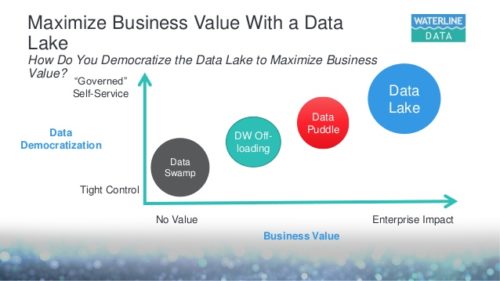 The ability to harness more data, from more sources, in less time, and empowering users to collaborate and analyze data in different ways leads to better, faster decision making. Examples where Data Lakes have added value include:
The ability to harness more data, from more sources, in less time, and empowering users to collaborate and analyze data in different ways leads to better, faster decision making. Examples where Data Lakes have added value include:
Improved customer interactions
Improve R&D innovation choices
Increase operational efficiencies
The Internet of Things (IoT) introduces more ways to collect data on processes like manufacturing, with real-time data coming from internet connected devices. A data lake makes it easy to store, and run analytics on machine-generated IoT data to discover ways to reduce operational costs, and increase quality.
DATA LAKE - CHALLENGES AND FUTURE
CHALLENGES
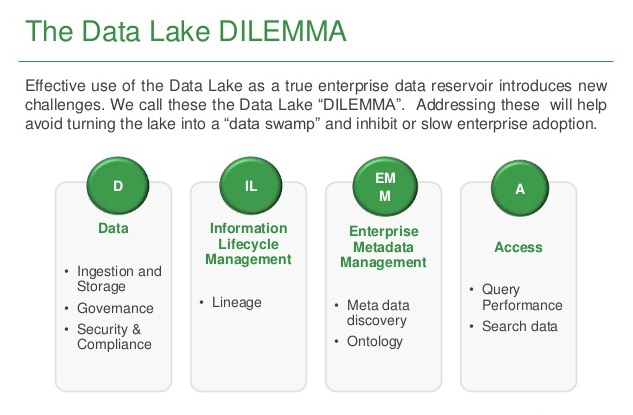 The main challenge with a data lake architecture is that raw data is stored with no oversight of the contents. For a data lake to make data usable, it needs to have defined mechanisms to catalog, and secure data. Without these elements, data cannot be found, or trusted resulting in a “data swamp." Meeting the needs of wider audiences require data lakes to have governance, semantic consistency, and access controls.
The main challenge with a data lake architecture is that raw data is stored with no oversight of the contents. For a data lake to make data usable, it needs to have defined mechanisms to catalog, and secure data. Without these elements, data cannot be found, or trusted resulting in a “data swamp." Meeting the needs of wider audiences require data lakes to have governance, semantic consistency, and access controls.
Meta Data Management
A data lake is only truly valuable to an organisation if its data is tagged and cataloged. Tagged data ensure better queries and better analysis. For example, metadata is a vital component of a data lake. Metadata provides context, which is vital in a data-driven world where we have data from multiple sources.
Twitter is very good at this. In fact, each tweet collects 65 data elements used to provide context for each tweet. Metadata enables us to combine and mix data to achieve insights that will transform your business.
Unfortunately, applying the right metadata at the right moment to the right data within the data lake can be a challenge. Adding metadata as soon as the data is entered in the data lake is a best practice, but it is not a common practice. Furthermore, there are not many tools available on the market that can assist in that.
One of the companies that actually has developed a system of automatically adding the right metadata upon data ingestion in the lake is Zaloni. Their product, which is called Bedrock, provides significant automated metadata capabilities that can enrich your raw data and provide the context required to make the most of your data, thereby solving a big challenge linked to current data lakes.
Data Governance
Data governance is a challenge for any organisation dealing with data in general and big data specifically. But when it comes to data lakes, this becomes even more important. If data governance is not taken care off when starting with a data lake, you can enter ‘data limbo land’ where all kinds of issues related to data quality, metadata management or security could arise, causing your data lake to fail dramatically.
The right processes should be in place within your organisation to ensure that data governance is done correctly and to ensure that the right data is stored correctly and the right and correct algorithms are used to analyse your data.
Data Preparation
Another challenge is to ensure proper dealing with the data. As more democratized access to the lake is allowed, and self-service becomes more common, finding ways to address data quality and preparation becomes ever more critical.
There are two distinct options to ensure proper data preparation: 1) employ the right data scientists who understand how to create sophisticated analytics models while ensuring data quality and data lineage or 2) use a system that prepares the raw data (semi-) automatically and thereby enable end-users to easily query the data and/or import in different analytical tools to gain insights from the data.
The first option might not be suitable, because hiring, or training, data scientists is expensive and sometimes that is not possible for an organisation. The second option becomes more and more available since Big Data vendors are developing tools to do this automatically.
One of these tools is Mica, which enables self-service data preparation enabling end-users to work with the raw data how they want, collaborate with the data and analyse it using different analytical tools. The main advantage is that business users don’t have to wait until IT has done the data preparation, because they can do it themselves. Mica even enables users to operationalise the data preparation so that it will happen automatically when relevant new data enters the lake.
Data Security
Of course, when you have all data in one central location, security becomes an issue. Already too many organisations have experienced data breaches, and when your data lake is breached, it seriously could mean the end of your business. Therefore, the ‘standard’ security measures should be in place.
However, having your data stored in one place has an additional security issue. Therefore, role-based access is of extreme importance when building a data lake. The data lake should ensure that although the data is stored in one central location, access is determined based on the role you have. To enforce this, you can for example tag metadata with security data to ensure that role-based access is also implemented on the metadata level.
FUTURE OF DATA LAKE
Data Lake Market: 2020 – 2025
 With the shift towards cloud-based data platforms to manage and mitigate data issues expected to offer opportunities for data lake solution adoption further, MarketsandMarkets expects the global data lake market to grow at a CAGR of 20.6 percent until 2024.
With the shift towards cloud-based data platforms to manage and mitigate data issues expected to offer opportunities for data lake solution adoption further, MarketsandMarkets expects the global data lake market to grow at a CAGR of 20.6 percent until 2024.
According to the research report, announced in early 2020, the global data lake market size is forecasted to reach $20.1 billion by 2024, coming from an estimated $7.9 billion in 2019.
Another report, by Mordor Intelligence, values the data lake market in 2019 at $3.74 billion, expecting it to reach $17.6 billion by 2025 or a CAGR of 29.9 percent over the forecast period 2020-2025. Below are some of the Future Trends to watch for in Data Lake Industry and solutions.
In-data-lake BI solutions
The data lake landscape evolves fast, the essence is still about turning data into value and the means to do this better, the solutions that exists since those early days, ample trends on the technology front and the lessons learned, make it hard to compare the past of data lakes with their present, let alone future, a future that looks pretty bright with many organizations indicating they have plans to deploy a data lake, with a shift to the cloud.
Data Lake and Cloud
It’s clear that the future of data lakes is cloud. Although there will be exceptions for some industries because of regulatory issues and a traditionally more careful approach towards when it comes to public cloud. However, cloud is scalable and it can be expanded fast as it does overall in other business areas.
Big Data Evolution
These days Big Data is everywhere. Big data is data and the question is what to do with it. Although that remains the question most professionals still get from organizations (‘what do I do with all that data to benefit from it?’) overall data maturity has increased and new generations of experts know that big data analytics is the crux of the matter to reap value and that you don’t approach data the same way as you used to in the days of traditional data warehouses – the mindset and culture regarding leveraging big data has evolved and will continue to evolve with with the developments in the new data lake solutions.
Comments (3 Comments)























{kind=link}
Leave a Reply