




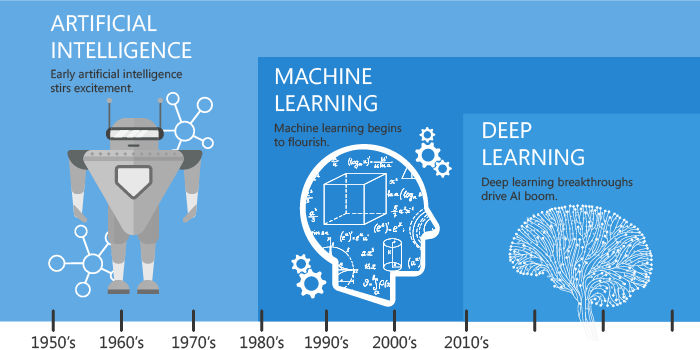
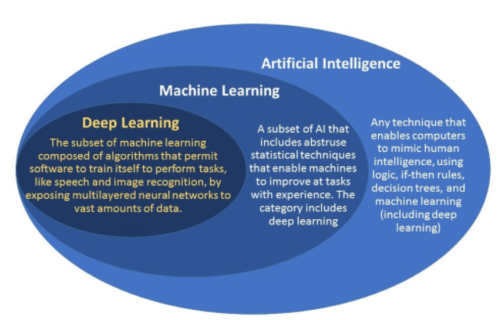
Deep learning also known as deep structured learning or hierarchical learning is part of machine learning based on artificial neural networks. This learning methodology can be supervised, semi-supervised or unsupervised.
Deep learning architectures such as neural networks and convolutional neural networks have been applied to fields including computer vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation where they have produced results comparable to and in some cases superior to human experts.
Brief History
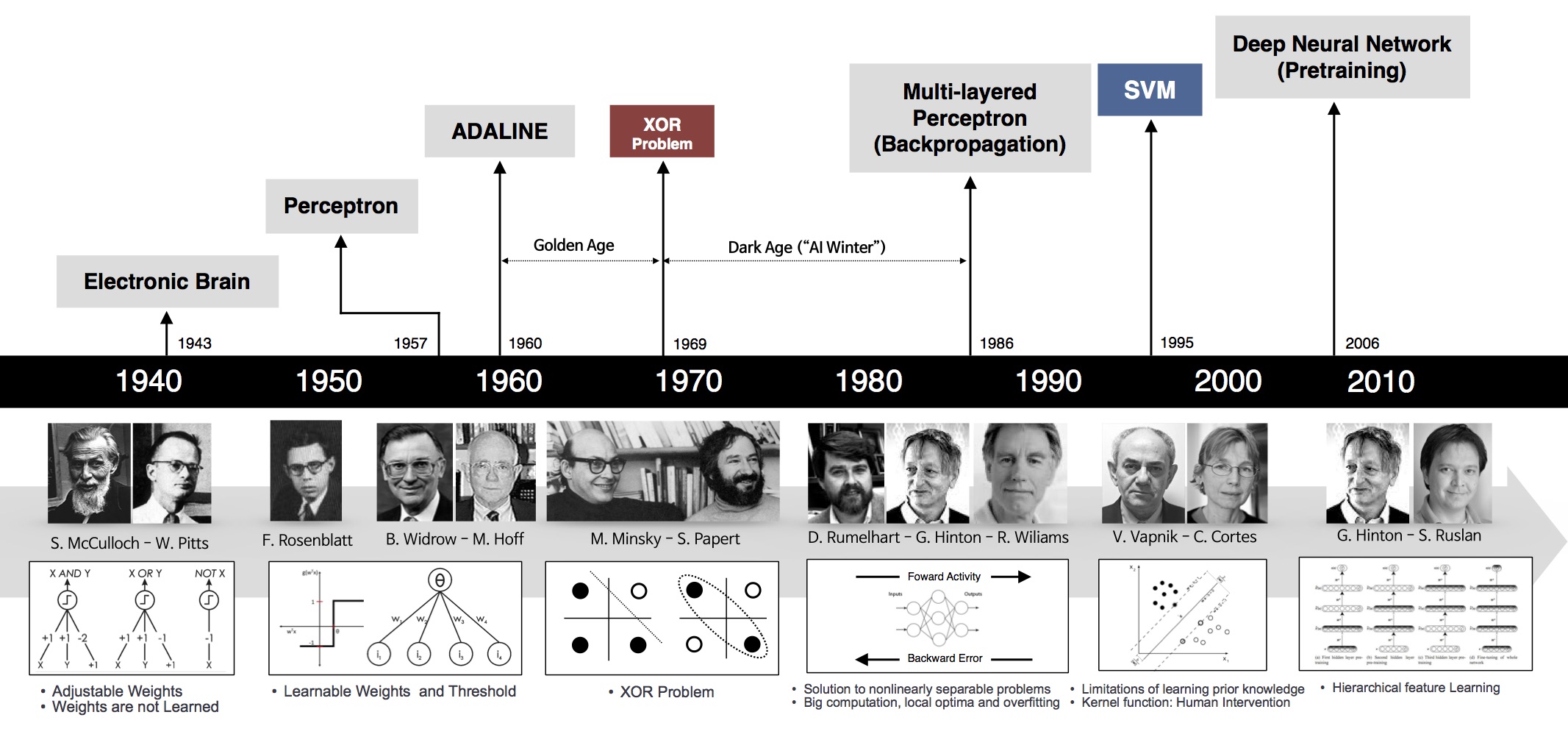
1943: The history of Deep Learning can be traced back to 1943, when Walter Pitts and Warren McCulloch created a computer model based on the neural networks of the human brain. They used a combination of algorithms and mathematics they called “threshold logic” to mimic the thought process. Since that time, Deep Learning has evolved steadily, with only two significant breaks in its development. Both were tied to the infamous Artificial Intelligence winters.
 1960: Henry J. Kelley is given credit for developing the basics of a continuous Back Propagation Model in 1960. In 1962, a simpler version based only on the chain rule was developed by Stuart Dreyfus. While the concept of back propagation (the backward propagation of errors for purposes of training) did exist in the early 1960s, it was clumsy and inefficient, and would not become useful until 1985.
1960: Henry J. Kelley is given credit for developing the basics of a continuous Back Propagation Model in 1960. In 1962, a simpler version based only on the chain rule was developed by Stuart Dreyfus. While the concept of back propagation (the backward propagation of errors for purposes of training) did exist in the early 1960s, it was clumsy and inefficient, and would not become useful until 1985.
The earliest efforts in developing Deep Learning algorithms came from Alexey Grigoryevich Ivakhnenko (developed the Group Method of Data Handling) and Valentin Grigorʹevich Lapa (author of Cybernetics and Forecasting Techniques) in 1965. They used models with polynomial (complicated equations) activation functions, that were then analyzed statistically. From each layer, the best statistically chosen features were then forwarded on to the next layer (a slow, manual process).
1970: During the 1970’s the first AI winter kicked in, the result of promises that couldn’t be kept. The impact of this lack of funding limited both DL and AI research. Fortunately, there were individuals who carried on the research without funding.
The first “convolutional neural networks” were used by Kunihiko Fukushima. Fukushima designed neural networks with multiple pooling and convolutional layers. In 1979, he developed an artificial neural network, called Neocognitron, which used a hierarchical, multilayered design. This design allowed the computer the “learn” to recognize visual patterns. The networks resembled modern versions, but were trained with a reinforcement strategy of recurring activation in multiple layers, which gained strength over time. Additionally, Fukushima’s design allowed important features to be adjusted manually by increasing the “weight” of certain connections.
Many of the concepts of Neocognitron continue to be used. The use of top-down connections and new learning methods have allowed for a variety of neural networks to be realized. When more than one pattern is presented at the same time, the Selective Attention Model can separate and recognize individual patterns by shifting its attention from one to the other. (The same process many of us use when multitasking). A modern Neocognitron can not only identify patterns with missing information (for example, an incomplete number 5), but can also complete the image by adding the missing information. This could be described as “inference.”
Back propagation, the use of errors in training Deep Learning models, evolved significantly in 1970. This was when Seppo Linnainmaa wrote his master’s thesis, including a FORTRAN code for back propagation. Unfortunately, the concept was not applied to neural networks until 1985. This was when Rumelhart, Williams, and Hinton demonstrated back propagation in a neural network could provide “interesting” distribution representations. Philosophically, this discovery brought to light the question within cognitive psychology of whether human understanding relies on symbolic logic (computationalism) or distributed representations (connectionism). In 1989, Yann LeCun provided the first practical demonstration of backpropagation at Bell Labs. He combined convolutional neural networks with back propagation onto read “handwritten” digits. This system was eventually used to read the numbers of handwritten checks.
1980-90: This time is also when the second AI winter (1985-90s) kicked in, which also effected research for neural networks and Deep Learning. Various overly-optimistic individuals had exaggerated the “immediate” potential of Artificial Intelligence, breaking expectations and angering investors. The anger was so intense, the phrase Artificial Intelligence reached pseudoscience status. Fortunately, some people continued to work on AI and DL, and some significant advances were made. In 1995, Dana Cortes and Vladimir Vapnik developed the support vector machine (a system for mapping and recognizing similar data). LSTM (long short-term memory) for recurrent neural networks was developed in 1997, by Sepp Hochreiter and Juergen Schmidhuber.
The next significant evolutionary step for Deep Learning took place in 1999, when computers started becoming faster at processing data and GPU (graphics processing units) were developed. Faster processing, with GPUs processing pictures, increased computational speeds by 1000 times over a 10 year span. During this time, neural networks began to compete with support vector machines. While a neural network could be slow compared to a support vector machine, neural networks offered better results using the same data. Neural networks also have the advantage of continuing to improve as more training data is added.
 2000: Around the year 2000, The Vanishing Gradient Problem appeared. It was discovered “features” (lessons) formed in lower layers were not being learned by the upper layers, because no learning signal reached these layers. This was not a fundamental problem for all neural networks, just the ones with gradient-based learning methods. The source of the problem turned out to be certain activation functions. A number of activation functions condensed their input, in turn reducing the output range in a somewhat chaotic fashion. This produced large areas of input mapped over an extremely small range. In these areas of input, a large change will be reduced to a small change in the output, resulting in a vanishing gradient. Two solutions used to solve this problem were layer-by-layer pre-training and the development of long short-term memory.
2000: Around the year 2000, The Vanishing Gradient Problem appeared. It was discovered “features” (lessons) formed in lower layers were not being learned by the upper layers, because no learning signal reached these layers. This was not a fundamental problem for all neural networks, just the ones with gradient-based learning methods. The source of the problem turned out to be certain activation functions. A number of activation functions condensed their input, in turn reducing the output range in a somewhat chaotic fashion. This produced large areas of input mapped over an extremely small range. In these areas of input, a large change will be reduced to a small change in the output, resulting in a vanishing gradient. Two solutions used to solve this problem were layer-by-layer pre-training and the development of long short-term memory.
In 2001, a research report by META Group (now called Gartner) described he challenges and opportunities of data growth as three-dimensional. The report described the increasing volume of data and the increasing speed of data as increasing the range of data sources and types. This was a call to prepare for the onslaught of Big Data, which was just starting.
In 2009, Fei-Fei Li, an AI professor at Stanford launched ImageNet, assembled a free database of more than 14 million labeled images. The Internet is, and was, full of unlabeled images. Labeled images were needed to “train” neural nets. Professor Li said, “Our vision was that Big Data would change the way machine learning works. Data drives learning.”
By 2011, the speed of GPUs had increased significantly, making it possible to train convolutional neural networks “without” the layer-by-layer pre-training. With the increased computing speed, it became obvious Deep Learning had significant advantages in terms of efficiency and speed. One example is AlexNet, a convolutional neural network whose architecture won several international competitions during 2011 and 2012. Rectified linear units were used to enhance the speed and dropout.
Also in 2012, Google Brain released the results of an unusual project known as The Cat Experiment. The free-spirited project explored the difficulties of “unsupervised learning.” Deep Learning uses “supervised learning,” meaning the convolutional neural net is trained using labeled data (think images from ImageNet). Using unsupervised learning, a convolutional neural net is given unlabeled data, and is then asked to seek out recurring patterns.
The Cat Experiment used a neural net spread over 1,000 computers. Ten million “unlabeled” images were taken randomly from YouTube, shown to the system, and then the training software was allowed to run. At the end of the training, one neuron in the highest layer was found to respond strongly to the images of cats. Andrew Ng, the project’s founder said, “We also found a neuron that responded very strongly to human faces.” Unsupervised learning remains a significant goal in the field of Deep Learning.
The Cat Experiment works about 70% better than its forerunners in processing unlabeled images. However, it recognized less than a 16% of the objects used for training, and did even worse with objects that were rotated or moved.
Currently, the processing of Big Data and the evolution of Artificial Intelligence are both dependent on Deep Learning. Deep Learning is still evolving and in need of creative ideas.
Functioning of Deep Learning
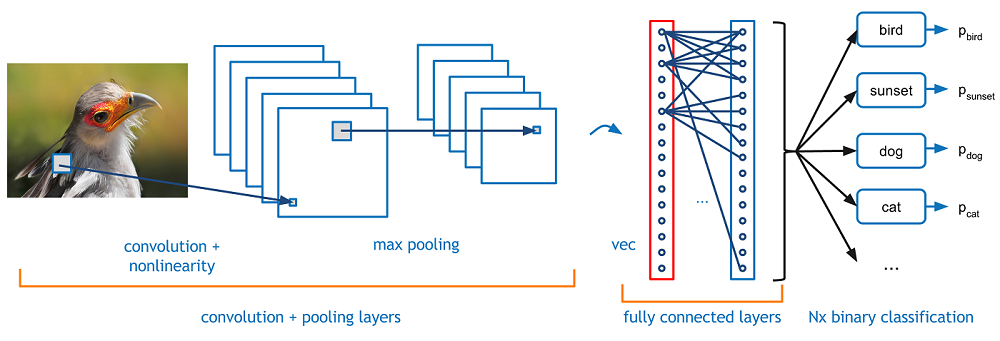
Deep learning models are trained by using large sets of labeled data and neural network architectures that learn features directly from the data without the need for manual feature extraction.
Creating and Training Deep Learning Models
The three most common ways people use deep learning to perform object classification are:
Training from Scratch
 To train a deep network from scratch, you gather a very large labeled data set and design a network architecture that will learn the features and model. This is good for new applications, or applications that will have a large number of output categories. This is a less common approach because with the large amount of data and rate of learning, these networks typically take days or weeks to train.
To train a deep network from scratch, you gather a very large labeled data set and design a network architecture that will learn the features and model. This is good for new applications, or applications that will have a large number of output categories. This is a less common approach because with the large amount of data and rate of learning, these networks typically take days or weeks to train.
Transfer Learning
Feature Extraction
Accelerating Deep Learning Models with GPUsTraining a deep learning model can take a long time, from days to weeks. Using GPU acceleration can speed up the process significantly. GPU reduces the time required to train a network and can cut the training time for an image classification problem from days down to hours. In training deep learning models, GPUs (when available) without requiring you to understand how to program GPUs explicitly.
Future Trends for Deep Learning

According to a leading source, the deep learning market is expected to exceed $18 billion by 2024, growing at a CAGR of 42%. Deep learning algorithms have a huge potential and take messy data like video, images, audio recordings, and text to make business-friendly predictions. Deep learning systems form a strong foundation of modern online services, used by giants like Amazon to understand what the users say understanding speech and the language they use through Alexa virtual assistant or by Google to translate text when the users visit a foreign-language website.
2019 and years to come will be dominated by deep learning trends that will create a disrupting impact in the technology and business world, here are the Top 5 Deep Learning Trends that will dominate 2019.
1. Training Datasets Bias will Influence AI
Human bias is a significant challenge for a majority of decision-making models. The difference and variability of artificial intelligence algorithms are based on the inputs they are fed. Data scientists have come to a conclusion that even machine learning solutions have their own biases that may compromise on the integrity of their data and outputs. Artificial intelligence biases can go undetected for a number of reasons, prominently being training data biases. Bias in training datasets impacts real-world applications that have come up from the biases in machine learning datasets including poorly targeted web-based marketing campaigns, racially discriminatory facial recognition algorithms and gender recruiting biases on employment websites.
2. AI will Rise Amongst Business and Society
Gone are the times when AI was the toast of sci-fi movies, but technology has finally caught up with imagination and adaptability. In the present times, AI has become a reality and amazingly, business and society encounter some form of artificial intelligence in their everyday operations.
Deep learning has dramatically improved the way we live and interact with technology. Amazon’s deep learning offering Alexa is powered to carry out a number of functions via voice interactions, like playing music, making online purchases and answering factual questions. Amazon’s latest offering, AmazonGo that works on AI allows shoppers to walk out of a shop with their shopping bags and automatically get charged with a purchase invoice sent directly to their phone.
3. AI Reality, the Hype will Outrun Reality
Deep learning powered Robots that serve dinner, self-driving cars and drone-taxis could be fun and hugely profitable but exists in far off future than the hype suggests. The overhype surrounding AI and deep learning will propel venture capitalists to redirect their capital elsewhere to the next big thing like 4d printing or quantum computing. Entry bars for deep learning project investments will be higher and at that point, the AI bubble will plunge. To avoid that, technology needs to help users to recognize that AI, machine learning, and deep learning are much more than just buzzwords and have the power to make our every day much easier. Reality says the time is ripe to spend fewer efforts on the exploration of deep learning possibilities and instead focus on delivering solutions to actual, real-life problems.
4. Solving The ‘Black Box’ Problem with Audit Trails
AI and its adaptability come with one of the biggest barriers to its deployment particularly in regulated industries, is the explanation as to how AI reached a decision and gave its predictions. 2019 will mark a new era in creating AI audit trails explaining the nitty-gritties of how AI and deep learning reach a conclusion.
In the future times to come, AI will be explored and deployed for groundbreaking applications like drug discovery which can have a detrimental impact on human life if an incorrect decision is made. Thus, audit trails to AI and deep learning predictions are extremely important.
5. AI Innovations will be Built on Cloud Adoption Capabilities
Come 2019 and beyond and business enterprises will seek to improve their technological infrastructure and cloud hosting processes for supporting their machine learning and AI efforts. As deep learning makes businesses innovate and improve with their machine learning and artificial intelligence offerings, more specialized tooling and infrastructure will be needed to be hosted on the cloud to support customised use cases, like solutions for merging multi-modal sensory inputs for human interaction (like think sound, touch, and vision) or solutions for merging satellite imagery with financial data for enhanced trading capabilities.
Comments (7 Comments)






























Leave a Reply