



Information Management Definition
Information Management (IM) is the process by which relevant information is provided to decision-makers in a timely manner. Information management has largely been defined from an information systems perspective and equated with the management of information technology. IM is a generic term that encompasses all the systems and processes within organisations for the creation and use of corporate information. IM aims to get the right information to the right person at the right place and at the right time (Robertson, 2005).
INFORMATION MANAGEMENT - PRINCIPLE AND COMPONENTS
Principles of Information Management
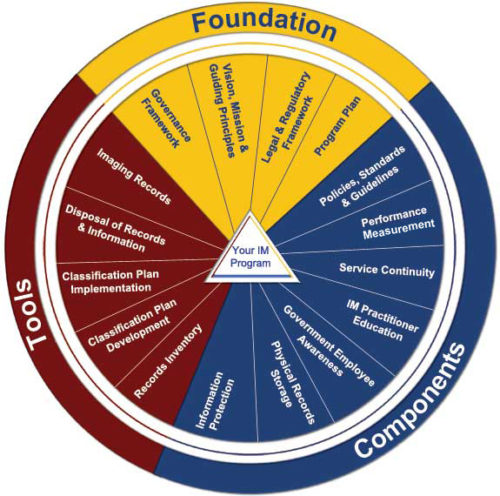 There are many information management principles. A well-known set is the Information Management Body of Knowledge (IMBOK), which is a framework that breaks down management skills into into six knowledge areas and four process areas mainly:
There are many information management principles. A well-known set is the Information Management Body of Knowledge (IMBOK), which is a framework that breaks down management skills into into six knowledge areas and four process areas mainly:
- Information Technology (IT): Hardware and software
- Information Systems: IT built into a system that meets business needs and policies
- Business Information: Created by analyzing and contextualizing data using tools such as the information system
- Business Processes: How to evaluate and use the business information to make decisions
- Business Benefit: The desired advantage the business information will provide
Key Components of Information Management:
Information management has four main components.
 People: Not only those involved in Information Management, but also the creators and users of Data and Information. These are the users who use the information system to record the day to day business transactions. The users are usually qualified professionals such as accountants, resource managers, etc. The ICT department usually has the support staff who ensure that the system is running properly.
People: Not only those involved in Information Management, but also the creators and users of Data and Information. These are the users who use the information system to record the day to day business transactions. The users are usually qualified professionals such as accountants, resource managers, etc. The ICT department usually has the support staff who ensure that the system is running properly.
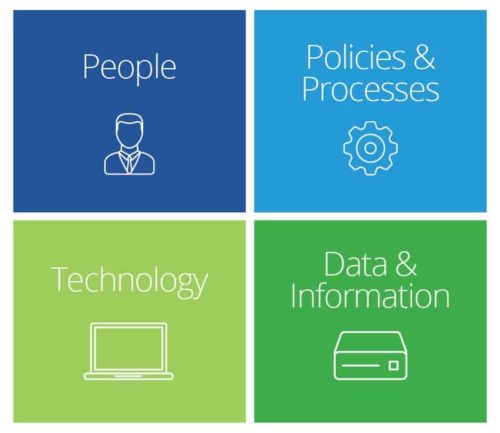 People: Not only those involved in Information Management, but also the creators and users of Data and Information. These are the users who use the information system to record the day to day business transactions. The users are usually qualified professionals such as accountants, resource managers, etc. The ICT department usually has the support staff who ensure that the system is running properly.
People: Not only those involved in Information Management, but also the creators and users of Data and Information. These are the users who use the information system to record the day to day business transactions. The users are usually qualified professionals such as accountants, resource managers, etc. The ICT department usually has the support staff who ensure that the system is running properly.- Policies and Processes: The rules that determine who has access to what, steps for how to store and secure information must be stored and secured, and time frames for archiving or deleting. These are agreed best practices that guide the users and all other components on how to work efficiently. Business procedures are developed by the people i.e. users, consultants, etc.
- Technology: The physical items (computers, filing cabinets, etc.) or Software that store data and information. Hardware – hardware is made up of the computers, printers, networking devices, etc. The hardware provides the computing power for processing data. It also provides networking and printing capabilities. The hardware speeds up the processing of data into information. Software – these are programs that run on the hardware. The software is broken down into two major categories namely system software and applications software. System software refers to the operating system i.e. Windows, Mac OS, and Ubuntu, etc. Applications software refers to specialized software for accomplishing business tasks such as a Payroll program, banking system, point of sale system, etc.
- Data and Information: Includes recorded day to day business transactions. Ex: For a bank, data is collected from activities such as deposits, withdrawals, etc.
Effective Implementation of an Information Management System -
 Increasing responsiveness and maximizing resources are important factors in how organizations improve their business in today’s data-driven, performance-based environment. The ability to deliver projects on time and within budget is one measure of performance.
Increasing responsiveness and maximizing resources are important factors in how organizations improve their business in today’s data-driven, performance-based environment. The ability to deliver projects on time and within budget is one measure of performance.
The effective delivery of a the assured services is fundamental to achieving an organization objective. A well designed and implemented information management system can substantially improve this capability. When it comes to Transportation or Logistics organization, adding geospatial capabilities (GIS) to the system to replace reliance on hardcopy maps and tabular information and to give additional management and analysis functions can significantly increase its usefulness.
Understanding these critical factors are necessary to successfully implement an Information Management System and ensure the best value for the resources invested and can substantially improve the realization of the system’s full potential. Obtaining strategic buy-in from agency executive-level decision makers to pursue implementation will provide the necessary foundation for system.
Implementing a System
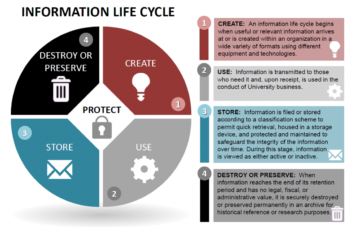 The process to implement an information management system should be well documented and for follow a standard procedures:
The process to implement an information management system should be well documented and for follow a standard procedures:
- Formalize support
- Assess requirements
- Assess capabilities
- Define the system
- Develop an implementation plan
- Implement the system
- Maintain the system
Implementation is typically considered complete at the point when the system being implemented has transitioned to “business as usual” for its users.
 Implementation Resources & Responsibilities
Implementation Resources & Responsibilities
 Implementation Resources & Responsibilities
Implementation Resources & Responsibilities- Implementation Leader / Project champion: This person is typically known and trusted by management and is responsible for marketing and promoting the system both inside and outside the Organisation. Without an identified champion, history has shown that projects flounder at the first major challenge.
- Steering group: The steering group is responsible for ensuring that there is active and appropriate input and feedback to the system during the implementation process. Transportation agencies consist of multiple departments and offices responsible for different aspects of doing business. Without representation from each group that will be impacted by the system, the system can face numerous challenges including: a) meeting information technology (IT) requirements, b) obtaining buy-in from stakeholders, and c) coordinating data sharing between data owners and users, as well as performing the tasks necessary to support right-of-way activities.
- Project manager: The project manager is responsible for the day-to-day management of the process. This person must have the necessary skills, authority and resources to coordinate sometimes conflicting input from the groups and individuals involved in the process. The project manager must also have the organizational skills to ensure that the process stays on track and within design boundaries and sufficient technical understanding of the right-of-way process and individual functions to reasonably evaluate input during the development process.
- Development team: The development team consists of the people who will actually be developing the system. They can be wholly from within the agency or wholly contracted from outside or a combination of both. The importance, at the proposal stage, is that the skills necessary to the project be clearly identified and articulated.
Implementation Factors
- Assessing requirements: Any proposal for a new information system should include a clearly stated understanding of the scope and goals of that system. As these requirements are refined, consideration should include the business areas to be included (often referred to as the enterprise), the functions that should be performed, the data needed to support these functions, other systems that should interact with the proposed system, security issues, and any legal and regulatory requirements.
- Assessing capabilities: An understanding of the capabilities in the right-of-way office and across the agency is critical to successfully implementing a system. Considerations include available or required hardware and software, existing applications including database management systems and GIS, datasets along with who is responsible for them, and agency policies and procedures related to IT including application development, data and data standards, and hardware and software acquisition. Knowing who will be responsible for maintaining the system and any corresponding data and output is also necessary. Availability of funding for development and continued maintenance is critical to the project’s success.
- Defining the system: This is the core of the system and will be the basis for the tool that manages the information associated with rightof-way offices. The technical considerations will be included in the detailed implementation plan. An important aspect of this definition is knowing the starting point for system development. Three common starting points include:
- The system is being developed from scratch with no existing information management system or GIS.
- The system is expanding on an existing information management system to include GIS.
- The system is being developed to take advantage of existing GIS capabilities.
Knowing this information will ensure that appropriate coordination is considered in the design.
Additional Considerations
The current evolution and expansion of technology is extremely rapid and most policies and procedures are not designed to operate at the same rate of change. Innovative and flexible approaches to supporting improved information management tools could save money and time both in their implementation and use.
From concept to operation, a comprehensive information management system can take 12 to 24 months or longer, and, during that time, technology changes or improvements are possible. Depending on more powerful, faster, and more flexible technologies will help in fingertip access to information. A flexible design can readily take advantage of this changing technology without requiring major modifications. However it is critical to remember that waiting for the next advancement before initiating the process can, and often does, result in never starting.
More and more Organisation are in the process of either designing or building an enterprise wide infrastructure for sharing data and/or integrating computer systems. Although, the desire to fold individual systems into this larger initiative is compelling, the reality may be more problematic given the scale, complexity, and cost of the larger effort.
With current technologies, consideration should be given to supporting individual systems if they provide the necessary connections to and support for integrating with the larger initiative.
Top 10 Future Trends of Information or Data Management
 Augmented Analytics
Augmented Analytics

Augmented analytics is the next wave of disruption in the data and analytics market. It uses machine learning (ML) and AI techniques to transform how analytics content is developed, consumed and shared.
By 2020, augmented analytics will be a dominant driver of new purchases of analytics and BI, as well as data science and ML platforms, and of embedded analytics. Information Management leaders should plan to adopt augmented analytics as platform capabilities mature.
Augmented Data Management
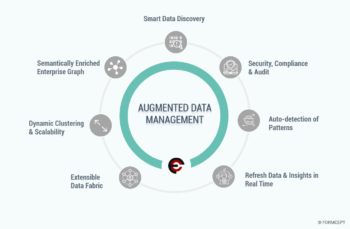 Augmented data management leverages ML capabilities and AI engines to make enterprise information management categories including data quality, metadata management, master data management, data integration as well as database management systems (DBMSs) self-configuring and self-tuning. It is automating many of the manual tasks and allows less technically skilled users to be more autonomous using data. It also allows highly skilled technical resources to focus on higher value tasks.
Augmented data management leverages ML capabilities and AI engines to make enterprise information management categories including data quality, metadata management, master data management, data integration as well as database management systems (DBMSs) self-configuring and self-tuning. It is automating many of the manual tasks and allows less technically skilled users to be more autonomous using data. It also allows highly skilled technical resources to focus on higher value tasks.
Augmented data management converts metadata from being used for audit, lineage and reporting only, to powering dynamic systems. Metadata is changing from passive to active and is becoming the primary driver for all AI/ML.
Through to the end of 2022, data management manual tasks will be reduced by 45 percent through the addition of ML and automated service-level management.
Continuous Intelligence
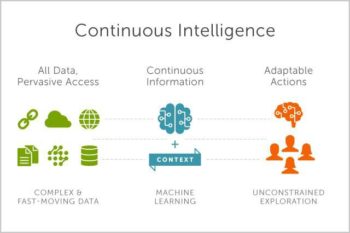 By 2022, more than half of major new business systems will incorporate continuous intelligence that uses real-time context data to improve decisions.
By 2022, more than half of major new business systems will incorporate continuous intelligence that uses real-time context data to improve decisions.
Continuous intelligence is a design pattern in which real-time analytics are integrated within a business operation, processing current and historical data to prescribe actions in response to events. It provides decision automation or decision support. Continuous intelligence leverages multiple technologies such as augmented analytics, event stream processing, optimization, business rule management and ML.
Continuous intelligence represents a major change in the job of the data and analytics team. It’s a grand challenge — and a grand opportunity — for analytics and BI (business intelligence) teams to help businesses make smarter real-time decisions in 2019. It could be seen as the ultimate in operational BI.”
ExplainableArtificial Intelligence(AI)
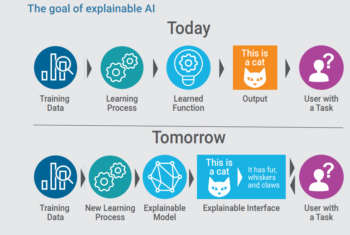 AI models are increasingly deployed to augment and replace human decision making. However, in some scenarios, businesses must justify how these models arrive at their decisions. To build trust with users and stakeholders, application leaders must make these models more interpretable and explainable.
AI models are increasingly deployed to augment and replace human decision making. However, in some scenarios, businesses must justify how these models arrive at their decisions. To build trust with users and stakeholders, application leaders must make these models more interpretable and explainable.
Unfortunately, most of these advanced AI models are complex black boxes that are not able to explain why they reached a specific recommendation or a decision. Explainable AI in data science and ML platforms, for example, auto-generates an explanation of models in terms of accuracy, attributes, model statistics and features in natural language.
Graphical Analytics
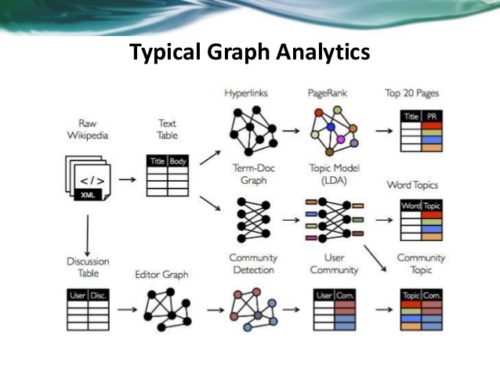 Graph analytics is a set of analytic techniques that allows for the exploration of relationships between entities of interest such as organizations, people and transactions.
Graph analytics is a set of analytic techniques that allows for the exploration of relationships between entities of interest such as organizations, people and transactions.
The application of graph processing and graph DBMS's will grow at 100 percent annually through 2022 to continuously accelerate data preparation and enable more complex and adaptive data science. Graph data stores can efficiently model, explore and query data with complex interrelationships across data silos, but the need for specialized skills has limited their adoption to date.
Graph analytics will grow in the next few years due to the need to ask complex questions across complex data, which is not always practical or even possible at scale using SQL queries.
Data Fabric
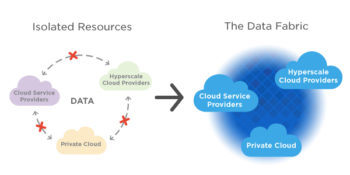 Data fabric enables friction less access and sharing of data in a distributed data environment. It enables a single and consistent data management framework, which allows seamless data access and processing by design across otherwise siloed storage.
Data fabric enables friction less access and sharing of data in a distributed data environment. It enables a single and consistent data management framework, which allows seamless data access and processing by design across otherwise siloed storage.
Through 2022, bespoke data fabric designs will be deployed primarily as a static infrastructure, forcing organizations into a new wave of cost to completely re-design for more dynamic data mesh approaches.
 Natural Language Processing(NLP) / Conversational Analytics
Natural Language Processing(NLP) / Conversational Analytics

By 2020, 50 percent of analytical queries will be generated via search, natural language processing (NLP) or voice, or will be automatically generated. The need to analyze complex combinations of data and to make analytics accessible to everyone in the organization will drive broader adoption, allowing analytics tools to be as easy as a search interface or a conversation with a virtual assistant.
 Commercial Artificial Intelligence (AI) and Machine Learning (ML)
Commercial Artificial Intelligence (AI) and Machine Learning (ML)
 Commercial Artificial Intelligence (AI) and Machine Learning (ML)
Commercial Artificial Intelligence (AI) and Machine Learning (ML)According to Gartner - by 2022, 75 percent of new end-user solutions leveraging AI and ML techniques will be built with commercial solutions rather than open source platforms.
Commercial vendors have now built connectors into the Open Source ecosystem and they provide the enterprise features necessary to scale and democratize AI and ML, such as project & model management, reuse, transparency, data lineage, and platform cohesiveness and integration that Open Source technologies lack.
Blockchain
 The core value proposition of blockchain, and distributed ledger technologies, is providing decentralized trust across a network of untrusted participants. The potential ramifications for analytics use cases are significant, especially those leveraging participant relationships and interactions.
The core value proposition of blockchain, and distributed ledger technologies, is providing decentralized trust across a network of untrusted participants. The potential ramifications for analytics use cases are significant, especially those leveraging participant relationships and interactions.
However, it will be several years before four or five major blockchain technologies become dominant. Until that happens, technology end users will be forced to integrate with the blockchain technologies and standards dictated by their dominant customers or networks. This includes integration with your existing data and analytics infrastructure. The costs of integration may outweigh any potential benefit. Blockchains are a data source, not a database, and will not replace existing data management technologies.
Persistent MemoryServers
 New persistent-memory technologies will help reduce costs and complexity of adopting in-memory computing (IMC)-enabled architectures. Persistent memory represents a new memory tier between DRAM and NAND flash memory that can provide cost-effective mass memory for high-performance workloads. It has the potential to improve application performance, availability, boot times, clustering methods and security practices, while keeping costs under control. It will also help organizations reduce the complexity of their application and data architectures by decreasing the need for data duplication.
New persistent-memory technologies will help reduce costs and complexity of adopting in-memory computing (IMC)-enabled architectures. Persistent memory represents a new memory tier between DRAM and NAND flash memory that can provide cost-effective mass memory for high-performance workloads. It has the potential to improve application performance, availability, boot times, clustering methods and security practices, while keeping costs under control. It will also help organizations reduce the complexity of their application and data architectures by decreasing the need for data duplication.
The amount of data is growing quickly and the urgency of transforming data into value in real-time is growing at an equally rapid pace. New server workloads are demanding not just faster CPU performance, but massive memory and faster storage.
Comments (8 Comments)


























Leave a Reply