



Computer vision is the technology which trains computers to understand and interpret the visual world. Using digital images from cameras, machine and deep learning models, computers can accurately identify and classify images or objects — and deliver accurate data or responses.
Early experiments in computer vision took place in the 1950s, using some of the first neural networks to detect the edges of an object and to sort simple objects into categories like circles and squares. In the 1970s, the first commercial use of computer vision interpreted typed or handwritten text using optical character recognition. This advancement was used to interpret written text for the blind.
As the internet matured in the 1990s, making large sets of images available online for analysis, facial recognition programs flourished. These growing data sets helped make it possible for machines to identify specific people in photos and videos.
How Computer Vision works
Critical Elements of Computer Vision
Acquiring an image - Images, even large sets, can be acquired in real-time through video, photos or 3D technology for analysis.
- High definition 2D / 3D Camera's
- Lighting Devices
- Lens
- Frames Grabber
- Image Processing Software
- Object detection - identifies a specific object in an image. Advanced object detection recognizes many objects in a single image: a football field, an offensive player, a defensive player, a ball and so on. These models use an X,Y coordinate to create a bounding box and identify everything inside the box.
- Facial recognition - is an advanced type of object detection that not only recognizes a human face in an image, but identifies a specific individual.
- Machine Learning Algorithms
- Pattern Recognition -Pattern detection is a process of recognizing repeated shapes, colors and other visual indicators in images.
- Image segmentation partitioning an image into multiple regions or pieces to be examined separately
- Edge detection is a technique used to identify the outside edge of an object or landscape to better identify what is in the image.
- Image classification groups images into different categories.
Digital Image Processing vs. Computer Vision -
Computer Vision is often confused with Image Processing, so it is very important to understand the differences between these two.
Image Processing - Digital image processing was pioneered at NASA’s Jet Propulsion Laboratory in the late 1960s, to convert analogue signals from the Ranger spacecraft to digital images with computer enhancement. Now, digital imaging has a wide range of applications, with particular emphasis on medicine. Well-known uses for it include Computed Aided Tomography (CAT) scanning and ultrasounds.
Image Processing is mostly related to the usage and application of mathematical functions and transformations over images regardless of any intelligent inference being done over the image itself. It simply means that an algorithm does some transformations on the image such as smoothing, sharpening, contrasting, stretching on the image.
Computer Vision - Computer vision comes from modelling image processing using the techniques of machine learning. Computer vision applies machine learning to recognize patterns for interpretation of images. Much like the process of visual reasoning of human vision; we can distinguish between objects, classify them, sort them according to their size, and so forth. Computer vision, like image processing, takes images as input and gives output in the form of information which users like to see viz. details of the image, size, color intensity etc.
Future Trends of Computer Vision:
Research in computer vision has been booming over the past few years, thanks to advances in deep learning, increases in computing storage, and the explosion of big visual data-sets. Every day, there are more computer vision applications in fields as diverse as autonomous vehicles, healthcare, retail, energy, linguistics, and more. Below are some of the Major trends that have dominated computer vision research.
Synthetic Data
Synthetic data has been a huge trend in computer vision research this past year. They are data generated artificially to train deep learning models. For example, the SUNCG dataset is used for simulated indoor environments, the Cityscapes dataset is used for driving and navigation, and the SURREAL dataset of synthetic humans is used to learn pose estimation and tracking. Let’s look at some of the best work utilizing synthetic data this year:
- The
 human ability to simultaneously learn from various information sources is still lacking in most existing feature learning approaches. Cross-Domain Self-supervised Multi-task Feature Learning using synthetic imagery addresses this gap by proposing an original multi-task deep learning network that uses synthetic imagery to better learn visual representations in a cross-modal setting. Training the network through synthetic images dramatically reduces data annotations needed for multitask learning, which is costly and time-consuming. To bridge the cross-domain gap between real and synthetic data, adversarial learning is employed in an unsupervised feature-level domain adaptation method, which enhances performance upon the transfer of acquired visual feature knowledge to real-world tasks.
human ability to simultaneously learn from various information sources is still lacking in most existing feature learning approaches. Cross-Domain Self-supervised Multi-task Feature Learning using synthetic imagery addresses this gap by proposing an original multi-task deep learning network that uses synthetic imagery to better learn visual representations in a cross-modal setting. Training the network through synthetic images dramatically reduces data annotations needed for multitask learning, which is costly and time-consuming. To bridge the cross-domain gap between real and synthetic data, adversarial learning is employed in an unsupervised feature-level domain adaptation method, which enhances performance upon the transfer of acquired visual feature knowledge to real-world tasks.
 human ability to simultaneously learn from various information sources is still lacking in most existing feature learning approaches.
human ability to simultaneously learn from various information sources is still lacking in most existing feature learning approaches.- Training Deep Networks with Synthetic Data proposes a refined approach for training deep neural network data for real
 object detection, relying on domain randomization of synthetic data. Domain randomization reduces the need for high-quality simulated data-sets by intentionally and randomly disturbing the environment’s textures to force the network to focus and identify the main features of the object. To augment the process’s performance, additional training on real data in conjunction with synthetic data is performed, which bridges the reality gap, therefore yielding better performance results. Different approaches were proposed to exploit the potential of synthetic data, which suggests this area will further advance in the coming years.
object detection, relying on domain randomization of synthetic data. Domain randomization reduces the need for high-quality simulated data-sets by intentionally and randomly disturbing the environment’s textures to force the network to focus and identify the main features of the object. To augment the process’s performance, additional training on real data in conjunction with synthetic data is performed, which bridges the reality gap, therefore yielding better performance results. Different approaches were proposed to exploit the potential of synthetic data, which suggests this area will further advance in the coming years.

Visual Question Answering
Visual question answering (VQA) is a new and exciting problem that combines NLP and computer vision techniques. It typically involves showing an image to a computer and asking a question about that image that the computer must answer. The answer could be in any of the following forms: a word, a phrase, a Yes/No answer, multiple choice answers, or a fill-in-the-blank answer.There have been various datasets developed recently to tackle this task, such as DAQUAR, Visual7W, COCO-QA, VQA. Let’s look at some of the best models in question answering this year.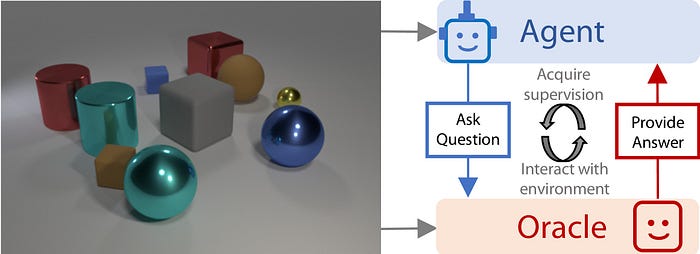
- Standard VQA models passively rely on large static datasets—unlike the interactive nature of human learning that’s more sample efficient and less redundant. Learning by asking questions fills this research gap by introducing a more interactive VQA model that mimics natural learning. In this paper, the agent is trained to learn like a human by evaluating its prior acquired knowledge and asking good and relevant questions that maximize the learning signal from each image-question pair sent to the oracle. The paper also shows how interactive questioning significantly reduces redundancy and the required number of training samples to achieve accuracy increases of 40%.

- Interactive QA addresses one of the shortcomings of standard VQA models, which are mostly passive and do not train a fully intelligent agent capable of navigating, interacting, and performing tasks within its environment. The model uses a multi-level controller method with semantic spatial memory and collects a rich dataset of simulated realistic scenes and a wide range of questions to evaluate the model. It advances standard VQA towards the ultimate goal of creating fully visually intelligent agents.
Domain Adaptation
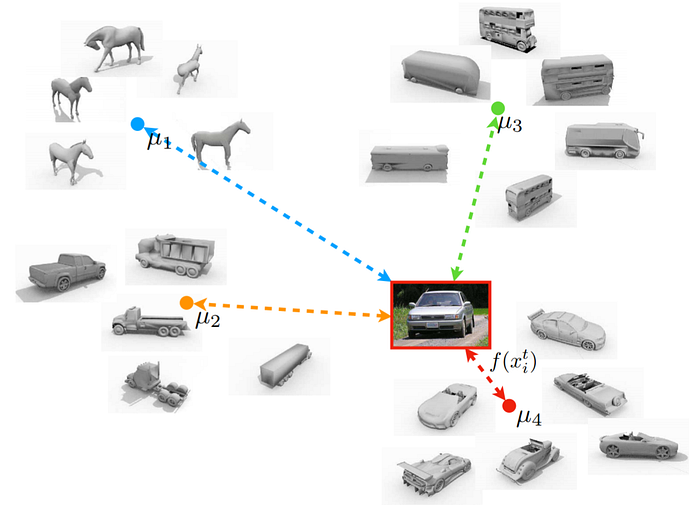
- Unsupervised Domain Adaptation with Similarity Learning deals with domain adaptation using adversarial networks. The author asks one network to extract features from a labeled source domain and another network to extract features from an unlabeled target domain, with similar but different data distribution. The classification in which the model is trained to discriminate the target prototype from all other prototypes is different. To label the image from the target domain, the author compares the embedding of an image with embeddings of prototype images from the source domain and then assigns the label of its nearest neighbors.

- Image to Image Translation for Domain Adaptation looks at domain adaptation for image segmentation, which is used widely in self-driving vehicles, medical imaging, and many other domains. Basically, domain adaptation techniques here must find a mapping structure from the source data distribution to the target data distribution. The approach uses 3 main techniques: (i) domain-agnostic feature extraction (the distributions of features extracted from both source and target domains are indistinguishable), (ii) domain-specific reconstruction (embeddings can be decoded back to the source and target domains), and (iii) cycle consistency (mappings are learned correctly).
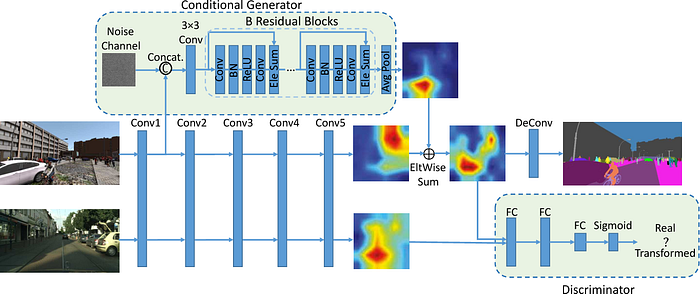
- Conditional GAN for Structured Domain Adaptation offers a new method to overcome the challenges of cross-domain differences in semantic segmentation models with a structured domain adaptation method. Unlike unsupervised domain adaptation, the method does not assume the existence of cross-domain common feature space, and rather employs a conditional generator and a discriminator. Therefore, a conditional GAN is integrated into the CNN framework that transfers features of synthetic images to real-image like features. The method results outperform previous models, highlighting the growing potential of synthetic datasets in advancing vision tasks.

- Training deep learning-based models relies on large annotated datasets, which requires lots of resources. Despite achieving state-of-the-art performance in many visual recognition tasks, cross-domain differences still constitute a big challenge. To transfer knowledge across domains, Maximum Classifier Discrepancy for Unsupervised Domain Adaptation uses a novel adversarial learning method for domain adaptation without a need for any labeling information from the target domain. It’s observed that minimizing the discrepancy between the probability estimates from two classifiers for samples from a target domain can produce class-discriminative features for various tasks, from classification to semantic segmentation.
Generative Adversarial Networks
Generative Adversarial Networks (GAN), the most successful class of generative models for computer vision. Let’s look at some of the best works that improve GAN models :
- Conditional GANs are already widely used for image modeling, but they are also very useful for style transfer. Particularly, they can learn salient features that correspond to specific image elements and then change them. In PairedCycleGAN for Makeup, the authors present a framework for makeup modification on photos. They train separate generators for different facial components and apply them separately, extracting facial components with a different network.

- Eye Image Synthesis with Generative Models looks at the problem of generating human eyes images. This is an interesting use case because we can use generated eyes to solve the gaze estimation problem — what is a person looking at? The authors use a probabilistic model of eye shape synthesis and a GAN architecture to generate eyes following that model.

- Generative Image In-painting with Contextual Attention looks at the challenging problem of filling in blanks on an image. Usually, we need to have an understanding of the underlying scene to do in-painting. This work instead uses a GAN model that can explicitly use features from the surrounding image to improve generation.

- Current state-of-the-art GAN-based text-to-image generation models encode textual descriptions only on the sentence level and overlook fine-grained information on the word-level that would improve the quality of generated images. AttnGAN proposes a novel word-level attention mechanism that’s far more impressive in producing complex scenes.

- In contrast to the common belief that the success of neural networks mainly comes from their strong ability to learn from data, Deep Image Prior demonstrates the importance of the structure of the network for building good image priors. The paper proposes a decoder network as a prior for imaging tasks. Interestingly enough, the authors show that a generator network is adequate to capture a large amount of low-level image statistics prior to any learning. The authors also use the approach to investigate the information content retained at different levels of the network by producing so-called natural pre-images. Intriguingly, using the deep image prior as a regularizer, the pre-image obtained from even very deep layers still captures a large amount of information.

- Despite the success of GANs, no considerable success has been reported on the usage of their discriminator network as a universal loss function for common supervised tasks such as semantic segmentation. Matching Adversarial Networks highlights the reason behind this, namely that the loss function does not directly depend on the ground truth labels during generator training, which leads to random production of samples from data distributions without correlating the input-output relations in a supervised fashion. To overcome this, the paper proposes replacing the discriminator with a matching network—while taking into account both the ground truth outputs as well as the generated examples—which is facilitated by a Siamese network architecture.
3D Object Understanding
3D object understanding is critical for deep learning systems to successfully interpret and navigate the real world. For instance, a network may be able to locate a car in a street image, color all of its pixels, and classify it as a car. But does it fully understand where the car in the image is, with respect to other objects in the street?The work in 3D object understanding spans a wide variety of research areas including object detection, object tracking, pose estimation, depth estimation, scene reconstruction, and more. Let’s cover major papers in this field in 2018: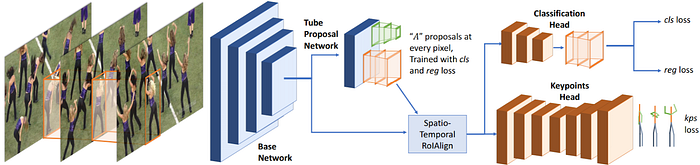
- Detect-and-Track is an extension of Mask R-CNN, one of the most promising approaches to image segmentation that appeared back in 2017. The authors propose a 3D Mask R-CNN architecture that uses spatiotemporal convolutions to extract features and recognize poses directly on short clips. The complete architecture can be seen below. It achieves state-of-the-art results in pose estimation and human tracking.

- Pose-Sensitive Embeddings for Person Re-Identification tackles the challenge of person re-identification. Usually, this problem is solved with retrieval-based methods that derive proximity measures between the query image and stored images from some embedding space. The paper instead proposes a novel way to incorporate information about the pose directly into the embedding and improve re-identification results. You can see the architecture below.
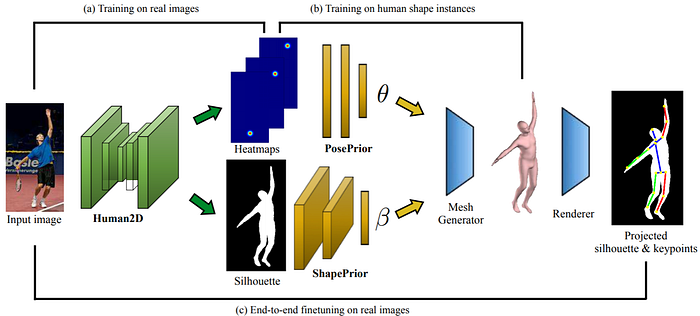
- 3D Poses from a Single Image presents a very surprising approach to pose estimation. It generates the 3D mesh of a human body directly through an end-to-end convolutional architecture that combines pose estimation, segmentation of human silhouettes, and mesh generation. The key insight is that it uses SMPL, a statistical body shape model that provides a good prior for the human body’s shape. Consequently, it manages to construct a 3D mesh of a human body from a single color image.

- Flow Track deals with the problem of object tracking. It’s an extension of discriminative correlation filters, which learn a filter that corresponds to the object and apply it to all video frames. The model architecture has a spatial-temporal attention mechanism that attends across different time frames in the video.
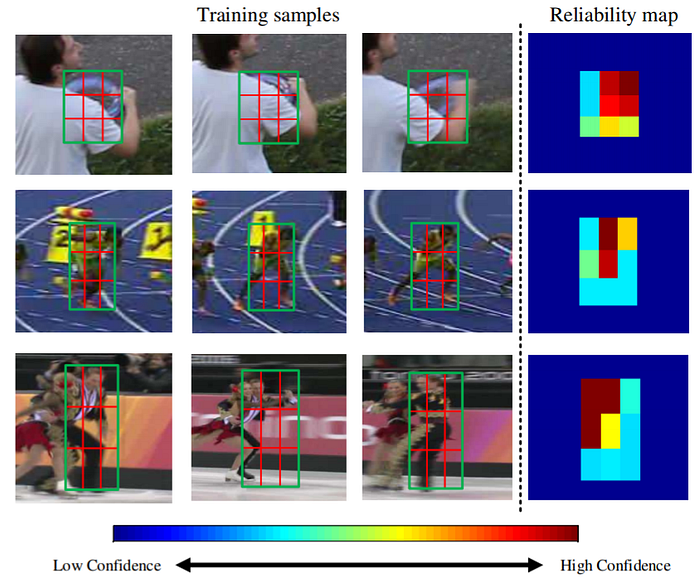
- Just like Flow Track described above, Correlation Tracking also deals with object tracking and also uses correlation filters. However, it doesn’t use a deep neural network; instead, it has reliability information — meaning that the authors add a term to the objective function that models how reliable the learned filter is.
Source Reference: https://www.sas.com/content/dam/SAS/documents/infographics/2019/en-computer-vision-110208.pdf https://heartbeat.fritz.ai/the-5-trends-that-dominated-computer-vision-in-2018-de38fbb9bd86 https://www.thomasnet.com/articles/top-suppliers/machine-vision-software-companies/
Comments (14 Comments)





































Leave a Reply