



Software consists of carefully-organized instructions and code written by programmers in any of various special computer languages. Organized Information in the form of operating system, utilities, programs and applications that enable computers to work.
Software is divided commonly into two main categories: System software: controls the basic (and invisible to the user) functions of a computer and comes usually preinstalled with the machine. See also BIOS and Operating System. Application software: handles multitudes of common and specialized tasks a user wants to perform, such as accounting, communicating, data processing, word processing.
DefinitionSoftware, by definition, is the collection of computer programs, procedures and documentation that performs different tasks on a computer system. The term 'software' was first used by John Tukey in 1958. At the very basic level, computer software consists of a machine language that comprises groups of binary values, which specify processor instructions. The processor instructions change the state of computer hardware in a predefined sequence. Briefly, computer software is the language in which a computer speaks.
Types of Software
There are different types of computer software.
- Programming Software:
- System Software:
- Application Software:
- Malware:
- Adware:
- Inventory Management Software:
- Utility Software:
- Data Backup and Recovery Software:
 This is one of the most commonly known and popularly used types of computer software. These software come in the form of tools that assist a programmer in writing computer programs. Computer programs are sets of logical instructions that make a computer system perform certain tasks. The tools that help programmers in instructing a computer system include text editors, compilers and interpreters. Compilers translate source code written in a programming language into the language which a computer understands (mostly the binary form). Compilers generate objects which are combined and converted into executable programs through linkers. Debuggers are used to check code for bugs and debug it. The source code is partially or completely simulated for the debugging tool to run on it and remove bugs if any. Interpreters execute programs. They execute the source code or a precompiled code or translate source code into an intermediate language before execution.
This is one of the most commonly known and popularly used types of computer software. These software come in the form of tools that assist a programmer in writing computer programs. Computer programs are sets of logical instructions that make a computer system perform certain tasks. The tools that help programmers in instructing a computer system include text editors, compilers and interpreters. Compilers translate source code written in a programming language into the language which a computer understands (mostly the binary form). Compilers generate objects which are combined and converted into executable programs through linkers. Debuggers are used to check code for bugs and debug it. The source code is partially or completely simulated for the debugging tool to run on it and remove bugs if any. Interpreters execute programs. They execute the source code or a precompiled code or translate source code into an intermediate language before execution.
 It helps in running computer hardware and the computer system. System software refers to the operating systems; device drivers, servers, windowing systems and utilities. System software helps an application programmer in abstracting away from hardware, memory and other internal complexities of a computer. An operating system provides users with a platform to execute high-level programs. Firmware and BIOS provide the means to operate hardware.
It helps in running computer hardware and the computer system. System software refers to the operating systems; device drivers, servers, windowing systems and utilities. System software helps an application programmer in abstracting away from hardware, memory and other internal complexities of a computer. An operating system provides users with a platform to execute high-level programs. Firmware and BIOS provide the means to operate hardware.
It enables the end users to accomplish certain specific tasks. Business software, databases and educational software are some forms of application software. Different word processors, which are dedicated to specialized tasks to be performed by the user, are other examples of application software.
Malware: Malware refers to any malicious software and is a broader category of software that are a threat to computer security. Adware, spyware, computer viruses, worms, trojan horses and scareware are malware. Computer viruses are malicious programs which replicate themselves and spread from one computer to another over the network or the Internet. Computer worms do the same, the only difference being that viruses need a host program to attach with and spread, while worms don't need to attach themselves to programs. Trojans replicate themselves and steal information. Spyware can monitor user activity on a computer and steal user information without their knowledge.
Malware refers to any malicious software and is a broader category of software that are a threat to computer security. Adware, spyware, computer viruses, worms, trojan horses and scareware are malware. Computer viruses are malicious programs which replicate themselves and spread from one computer to another over the network or the Internet. Computer worms do the same, the only difference being that viruses need a host program to attach with and spread, while worms don't need to attach themselves to programs. Trojans replicate themselves and steal information. Spyware can monitor user activity on a computer and steal user information without their knowledge.
 Adware is software with the means of which advertisements are played and downloaded to a computer. Programmers design adware as their tool to generate revenue. They do extract user information like the websites he visits frequently and the pages he likes. Advertisements that appear as pop-ups on your screen are the result of adware programs tracking you. But adware is not harmful to computer security or user privacy. The data it collects is only for the purpose of inviting user clicks on advertisements.
Adware is software with the means of which advertisements are played and downloaded to a computer. Programmers design adware as their tool to generate revenue. They do extract user information like the websites he visits frequently and the pages he likes. Advertisements that appear as pop-ups on your screen are the result of adware programs tracking you. But adware is not harmful to computer security or user privacy. The data it collects is only for the purpose of inviting user clicks on advertisements.
There are some other types of computer software like inventory management software, ERP, utility software, accounting software among others that find applications in specific information and data management systems. Let's take a look at some of them.
Inventory Management Software: This type of software helps an organization in tracking its goods and materials on the basis of quality as well as quantity. Warehouse inventory management functions encompass the internal warehouse movements and storage. Inventory software helps a company in organizing inventory and optimizing the flow of goods in the organization, thus leading to improved customer service.
This type of software helps an organization in tracking its goods and materials on the basis of quality as well as quantity. Warehouse inventory management functions encompass the internal warehouse movements and storage. Inventory software helps a company in organizing inventory and optimizing the flow of goods in the organization, thus leading to improved customer service.

Also known as service routine, utility software helps in the management of computer hardware and application software. It performs a small range of tasks. Disk defragmenters, systems utilities and virus scanners are some of the typical examples of utility software.
Data Backup and Recovery Software:An ideal data backup and recovery software provides functionalities beyond simple copying of data files. This software often supports user needs of specifying what is to be backed up and when. Backup and recovery software preserve the original organization of files and allow an easy retrieval of the backed up data.
Types of Software and their LicensingA software license determines the way in which that software can be accessed and used. Depending on the software licensing, the end users have rights to copy, modify or redistribute the software. While some software have to be bought, some are available for free on the Internet. Some licenses allow you to use, copy and distribute the software while others allow only one of the three operations. In some software, the source code is made available to the end users, while in others it is not. Here we will see the ways in which different types of software are distributed to users.
Custom Software:
Software that is developed for a specific user or organization is custom software. Since it is built for a specific user, its specifications and features are in accordance with the user's needs.
Off-the-Shelf Software:As opposed to custom software, off-the-shelf software is standard software bought off the shelf. It has predefined specifications that may or may not cater to any specific user's requirements. When you buy it, you agree to its license agreement.
Free Software: Software that a user is free to use, modify and distribute is known as free software. Free software generally comes free of cost but charges may be involved in distribution, servicing and maintenance. The term free refers to freedom of copying, distributing and modifying.
Software that a user is free to use, modify and distribute is known as free software. Free software generally comes free of cost but charges may be involved in distribution, servicing and maintenance. The term free refers to freedom of copying, distributing and modifying.
 In a closed source model, the source code is not released to public, while the source code is available for modification and use in open source software. Open source software is available in its source code form and the rights to change, improve and sometimes distribute its code are given under a software license. Software developed by an individual or an organization, where the source code is closed from public (not available openly) is referred to as closed source software.
In a closed source model, the source code is not released to public, while the source code is available for modification and use in open source software. Open source software is available in its source code form and the rights to change, improve and sometimes distribute its code are given under a software license. Software developed by an individual or an organization, where the source code is closed from public (not available openly) is referred to as closed source software.
 In proprietary software, legal rights remain exclusively with the copyright holder. Most proprietary software are available in the closed source form. Some vendors distribute proprietary software source code to the customers, however, with restricted access. Proprietary software is provided as shareware or demoware wherein users do not have to pay for use and it is distributed as trialware. There are no packaging costs involved. However the programmer may ask you to pay a small fee after which you are entitled to receive assistance and updates of that software.
In proprietary software, legal rights remain exclusively with the copyright holder. Most proprietary software are available in the closed source form. Some vendors distribute proprietary software source code to the customers, however, with restricted access. Proprietary software is provided as shareware or demoware wherein users do not have to pay for use and it is distributed as trialware. There are no packaging costs involved. However the programmer may ask you to pay a small fee after which you are entitled to receive assistance and updates of that software.
 While shareware is provided as a trial version to users, retail software is sold to end users. With the increasing availability of shareware and freeware on the web, the retail market is changing. Developers and vendors have started offering their software over the Internet. At times, shareware is made available as crippleware, wherein its main features do not work after the trial period has ended. In other words, such shareware has to be purchased to enable its crippled features. Though shareware is a very popular form in which software is distributed, retail software is not obsolete. Microsoft Office, for example, is a retail software package that has to be bought. Retail software may be given as an Original Equipment Manufacturer (OEM) Pack. Here, the software developer gives a licensed copy of the software to a computer manufacturer who installs it on computers before they are sold. In the Box Pack form, a licensed copy of the software is bought from an authorized retail outlet.
While shareware is provided as a trial version to users, retail software is sold to end users. With the increasing availability of shareware and freeware on the web, the retail market is changing. Developers and vendors have started offering their software over the Internet. At times, shareware is made available as crippleware, wherein its main features do not work after the trial period has ended. In other words, such shareware has to be purchased to enable its crippled features. Though shareware is a very popular form in which software is distributed, retail software is not obsolete. Microsoft Office, for example, is a retail software package that has to be bought. Retail software may be given as an Original Equipment Manufacturer (OEM) Pack. Here, the software developer gives a licensed copy of the software to a computer manufacturer who installs it on computers before they are sold. In the Box Pack form, a licensed copy of the software is bought from an authorized retail outlet.
This was an overview of the major types of software and their ways of distribution. Computer software are widely popular today and we cannot imagine computers without them. We would not have been able to use computers with so much ease, if not for software. What is fascinating about computers is that they have their own languages and their own ways of communicating with us humans. And their means to communicate are these different types of computer software.
TECHNOLOGICAL TRENDS: SOFTWARE DEVELOPMENT
Technology influences the way we develop software both through the affordances it provides (for example ample directly addressable main memory and multiple computing cores) and through the requirements it imposes (for instance the ability to analyze mountains of data). Second order effects also come to play when technological trends converge and feed on each other. One such example includes the convergence of cloud computing, big data analytics, and future networks. The following paragraphs outline the main technological trends that will affect software development in the next five to seven years and the corresponding challenges associated with software engineering.
SOFTWARE DEFINED ANYTHING AND INFRASTRUCTURE AS CODE (SDX/IAC)
Advances in raw hardware power and virtualization technologies are increasingly allowing the definition of sophisticated processing an d storage nodes through software. Particular instances of this phenomenon include software-defined networking (SDN), software-defined storage (SDS), and, on a larger-scale, software-defined data centers (SDDC). The common idea behind this software defined anything (SDx) trend is the provision of relatively dumb, but powerful and affordable hardware, and the implementation of higher-level functionality through configurable software. As a particular use case, consider software-defined networking, where the network’s control plane is implemented through software. A network switch is a simple and efficient forwarding table, and all additional functionality, such as routing and access control, is handled through (potentially centrally managed) software components. Other devices that are mainly defined through software include televisions, cameras, phones, engine and vehicle management systems, smart electricity grids, and home automation nodes.
d storage nodes through software. Particular instances of this phenomenon include software-defined networking (SDN), software-defined storage (SDS), and, on a larger-scale, software-defined data centers (SDDC). The common idea behind this software defined anything (SDx) trend is the provision of relatively dumb, but powerful and affordable hardware, and the implementation of higher-level functionality through configurable software. As a particular use case, consider software-defined networking, where the network’s control plane is implemented through software. A network switch is a simple and efficient forwarding table, and all additional functionality, such as routing and access control, is handled through (potentially centrally managed) software components. Other devices that are mainly defined through software include televisions, cameras, phones, engine and vehicle management systems, smart electricity grids, and home automation nodes.
From a software engineering perspective, the phenomenon is sometimes described through the term infrastructure as code (IaC). This entails large and small-scale infrastructure whose design and implementation is expressed through means that are indistinguishable from software code. As an example, consider a data center setup expressed in a system configuration management language, such as Puppet, Chef, or Ansible. The opportunity associated with this phenomenon is that such code must be developed and managed through processes that are essentially part of software engineering. The corresponding challenge is that the underlying artifacts do not behave as traditional code: for instance, debugging a software-defined data center is very different from debugging a Java program.
Furthermore, developers in this area are likely to be trained as domain experts rather than software engineers. Instilling a software engineering culture will be an uphill but rewarding struggle. Consequently, the corresponding research challenges are the following.
Cloud computing refers to the abstracted and on-demand provision and utilization of computing resources. It encompasses the provision of: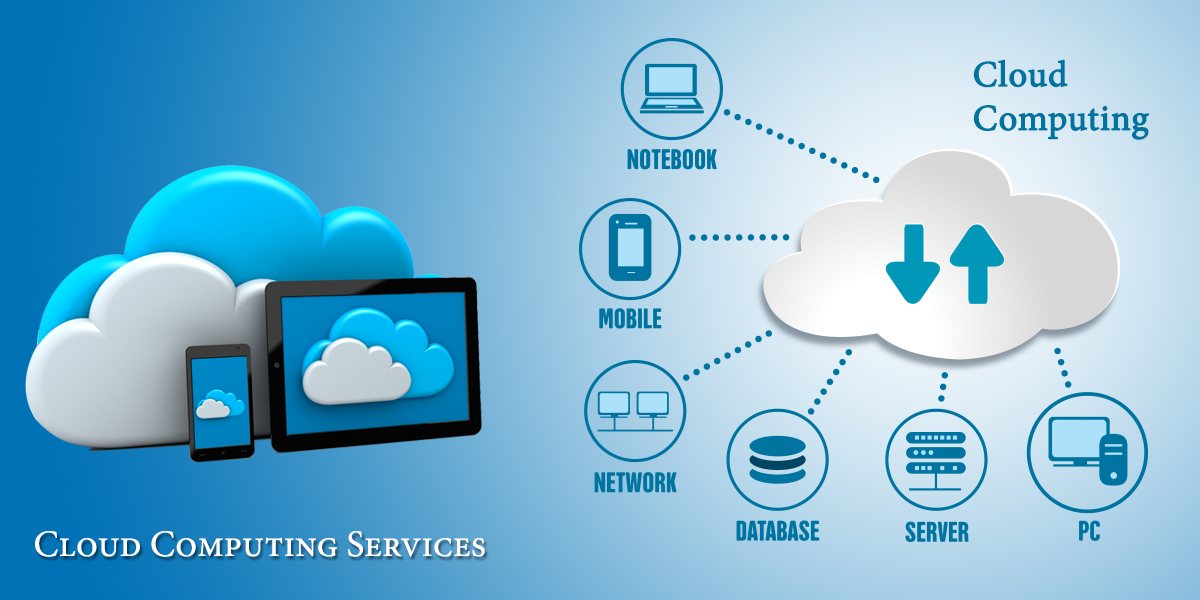
- unconfigured (virtual or real) hardware (processing nodes, storage, routers, load balancers) under the name infrastructure as a service (IaaS),
- middleware (runtime, application and web servers, databases, queues, directories) under the name platform as a service (PaaS), and complete applications (collaboration, office productivity, CRM, HRM, accounting) under the name of software as a service (SaaS).
- Although significant progress has been achieved in this area over the past decade, the extent of applications that are not benefiting from this technology indicates that the uptake’s scale will result in a qualitative rather than simply quantitative change in the field of software engineering.
A major task that software engineers must address, is the friction-free integration of IaaS, PaaS, and SaaS offerings with minimal vendor lock-in. This will benefit from cloud computing standardization and interoperability efforts, which will in turn require the definition of high-level services, APIs, and other abstractions. The corresponding research challenge is to devise suitable models, architectures, and design patterns that can address these needs. A challenge closer to the end-users is the ability to easily create reliable and efficient cloud computing mash ups based on software services and data.
The amount of innovation and growth that is likely to happen in the area of cloud computing, will spur the creation of a cloud-based economy where services, data, computing capacity, bandwidth, and other inputs will be traded, often in real time, based on current and projected demand and supply. Software engineers will be required both to define and implement the building blocks for the cloud-based economy, and write software that will efficiently utilize the provided resources. This will require the development of suitable methods, tools, as well as infrastructure, such as middleware, to efficiently utilize the provided resources. Specific research challenges in this area include the following.
- Efficient abstractions and container mechanisms that allow the efficient, scalable, robust, and secure utilization of cloud resources
- Tools for deploying, controlling and monitoring cloud-based services at a planetary scale
- Abstractions, libraries, and middleware for scaling applications deployed on the cloud and for reaping the benefits from economies of scale and scope

Personal mobile computing devices, digital social networks, scientific research, e-commerce, and the internet of things are generating a vast amount of data. Storing, processing, and analyzing these data is challenging, but can also be extremely rewarding to individuals, society, and the economy. This is, for example, the impetus behind the European Open Science Cloud, an initiative aiming to provide free, open, and seamless services for the storage, management, analysis, and re-use of research data. Software that handles big data will need to advance in order to cope with the demands of rising size, processing speed, and cost efficiency. This will require the development and deployment of appropriate architectures, frameworks, systems, tools, and libraries.
A specific software engineering challenge in this area include the development of architectures and formalisms that can efficiently express and implement big data processing operations. Another, equally important, research challenge is the introduction of software engineering methods and practices in the processing of big data — big data engineering.
UNIVERSAL MEMORY COMPUTING
The dynamic random access memory (DRAM) technology, which currently serves the vast bulk of computing’s main memory needs is reaching the limits of its 40 year evolution. Large trench aspect ratios and small apertures of individual DRAM cells are leading to seemingly
insurmountable quality problems. However, new types of memory technologies, such as spin-transfer torque RAM (STT-RAM), phase change memory (PCM), and the Memristor, can offer increased capacities through crossbar layouts and vertical stacking. In contrast to DRAM, these technologies have also the property of being non-volatile memory (NVM).
On the secondary storage side, a related technological change is happening through the adoption of (mainly NAND flash memory based) solid state drives (SSDs) in place of magnetic disks.
Both technological changes lead to a type of universal memory that combines the fast random access characteristics of DRAM with the non-volatility of disk storage. This calls for a different programming model that focuses entirely on main memory computation. The corresponding software-related challenges are two. The first challenge involves the creation of suitable abstractions and systems (such as operating systems, middleware, database research priorities in the Area of Software Technologies management systems, libraries, and frameworks) to support this model and benefit from it.
In particular, the paradigm shift of main memory computation creates space for new market entrance to establish foothold in the corresponding markets. The second challenge is the development of processes to adapt existing application software to the new technological landscape. Modern organizations depend on a colossal amount of what will become legacy software. Adapting it for the new paradigm will cost dearly, while staying behind leaves the field open to new nimbler players. Architectures, libraries, and tools that can lessen the conversion pain (e.g. by converting a legacy three-tier software architecture to use a main memory embedded database) can reduce the conversion’s cost and provide drastically more efficient applications.
MULTICORE ARCHITECTURE
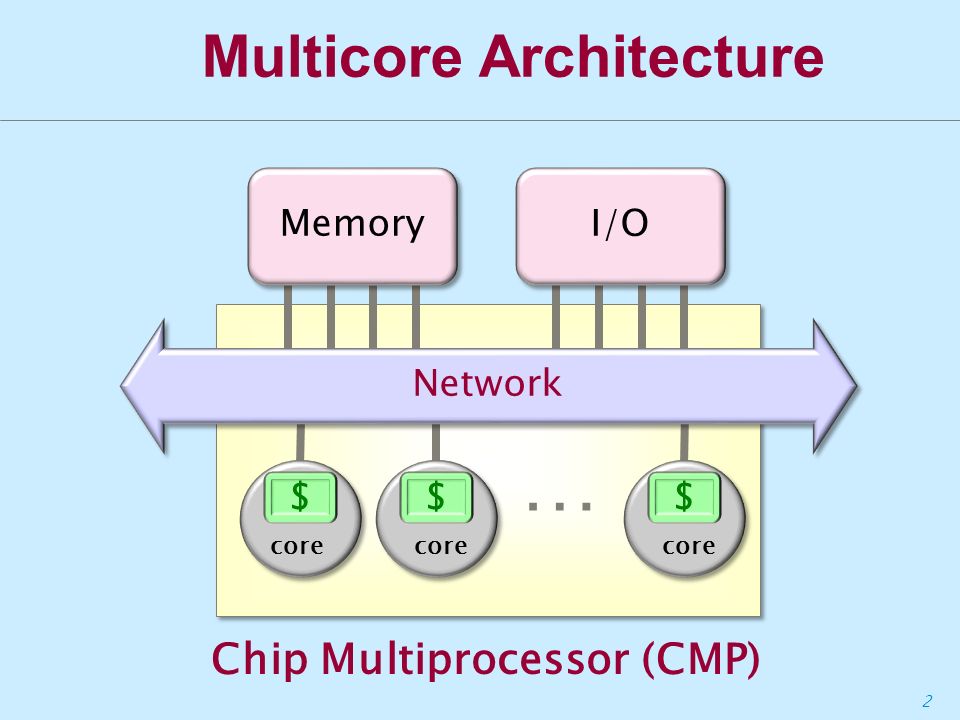
The main driver for the rise of multicore architectures is the energy cost of higher CPU frequencies. The dynamic switching power consumed by a CMOS microchip is proportional to the cube of its clock frequency. For example, halving the CPU’s frequency lowers its dynamic power requirements to 12.5% of the original; doubling the number of cores to compensate for the frequency reduction, will still require only 25% of the original power. In this case, further savings of power can be achieved through the reduction of static power by switching off one of the two cores when it’s not required. This trend affects enterprise and high-performance computing occurring in cloud-based servers, which cannot realistically rely on the rise of CPU frequencies to deliver the required computing capacity. It also affects energy-constrained embedded devices, such as mobile phones and IoT nodes, which must be very power efficient.
Currently, a serious obstacle in the use of multicore architectures is the gap between the skills of existing programmers and the skills required to effectively program them. In the words of David Patterson “parallelism can work when you can afford to assemble a crack team of Ph.D.-level programmers to tackle a problem with many different tasks that depend very little on one another”. Thus, on the software side, the rise of multicore architectures drives demand for software and systems architectures that can harness the multiple cores. This includes compiler technologies, parallelization methods, profiling tools, and software components that can efficiently exploit non-homogeneous multicore architectures, such as those with GPUs
 Quantum computing (QC) is based on the counterintuitive properties of quantum mechanical phenomena. Many algorithms that have formidable cost in classical computing infrastructures can be, in theory, efficiently executed on QC hardware. Small scale experiments have shown that this could be a realistic possibility. Current hardware is still at its infancy, with even the most advanced hardware supporting computation with around one thousand qubits (quantum bits). Yet, both commercial companies and researchers frequently report significant practical and theoretical progress, so this is an area where game-changing developments cannot be ruled out.
Quantum computing (QC) is based on the counterintuitive properties of quantum mechanical phenomena. Many algorithms that have formidable cost in classical computing infrastructures can be, in theory, efficiently executed on QC hardware. Small scale experiments have shown that this could be a realistic possibility. Current hardware is still at its infancy, with even the most advanced hardware supporting computation with around one thousand qubits (quantum bits). Yet, both commercial companies and researchers frequently report significant practical and theoretical progress, so this is an area where game-changing developments cannot be ruled out.
Practical QC will significantly affect software development, requiring a complete rethink of how software is expressed and structured (programming languages and architectures), what tools are used for its development (compilers and IDEs), and what software components and abstractions should be provided. Given the difficulty of constructing pure QC computing hardware, another significant area of development is the integration of classical computing with its quantum sibling.
NATURAL USER INTERFACES
The increased availability of multitouch sensors, microphones, accelerometers, and high resolution cameras on computing devices allows for a radically different way of communicating with them. This mode of interaction replaces or supplements the keyboard and mouse with touch, gestures, and speech giving rise to the so-called natural user interfaces (NUIs). Deployed on emerging settings ranging from mobile devices, to cars, to living rooms, these are increasingly used in a real-time networked fashion, providing the NUI makers with rich data regarding the interactions.
 The challenge for software adopting NUIs is to become increasingly intelligent and transparently responsive. Given the technology’s sophistication this capability should be provided at the systems level rather than separately for each application. Specifically, such software should integrate input from multiple sensors, predict user input, adjust according to context, infer intentions, resolve ambiguities through dialogue, and augment the users’ perception of reality. The related software engineering challenge concerns the development of reusable components and frameworks that can make this vision a reality.
The challenge for software adopting NUIs is to become increasingly intelligent and transparently responsive. Given the technology’s sophistication this capability should be provided at the systems level rather than separately for each application. Specifically, such software should integrate input from multiple sensors, predict user input, adjust according to context, infer intentions, resolve ambiguities through dialogue, and augment the users’ perception of reality. The related software engineering challenge concerns the development of reusable components and frameworks that can make this vision a reality.
Machine learning (ML) systems learn from data and then operate based on that knowledge. Notable applications include pattern recognition, natural language processing, and recommendation systems. Emerging approaches, such as deep learning, have led to remarkable practical successes in a number of areas. Two software-related challenges need to be addressed to increase the benefits that can be reaped from ML systems. First, the scalability of ML systems must be addressed in order to tame the processor and memory demands of current algorithms. This also entails the harnessing of new upcoming hardware capabilities to support ML computations at the software systems level. Second, to expand the reach of ML systems beyond large vertical areas into a wider range of applications, the ML systems’ configuration must be brought closer to the capabilities of non-experts.
natural language processing, and recommendation systems. Emerging approaches, such as deep learning, have led to remarkable practical successes in a number of areas. Two software-related challenges need to be addressed to increase the benefits that can be reaped from ML systems. First, the scalability of ML systems must be addressed in order to tame the processor and memory demands of current algorithms. This also entails the harnessing of new upcoming hardware capabilities to support ML computations at the software systems level. Second, to expand the reach of ML systems beyond large vertical areas into a wider range of applications, the ML systems’ configuration must be brought closer to the capabilities of non-experts.
Research in this area can look at domain-specific languages, specialized IDEs, and agile software development methods tailored to the development of ML systems.
THE EFFECT OF SOFTWARE IN VERTICAL APPLICATION DOMAINS
Software is increasingly becoming a cross-cutting, enabling technology for most information and communication technology (ICT) developments. Software technologies are driving and shaping many vertical application domains ranging from emerging ones, such as autonomous vehicles to long-established ones, such as life sciences. Therefore, research in software technologies is an enabler and a driver for these application domains.
Autonomous vehicles, once a staple transportation mode only in science fiction movies, are increasingly seen as an upcoming development that will change many aspects of the economy and modern life. An autonomous vehicle is a crucible for most areas of computing and software engineering: from artificial intelligence and signal processing, to sensor networks and user experience. Major challenges associated with software include the harnessing of the system’s complexity while achieving the required levels of performance, safety, and reliability.
OPEN INTELLECTUAL PROPERTY
The open intellectual property (IP) movement encompasses information, software, scientific publishing, media, protocols, systems, designs of physical artifacts, online courses, and printable 3D models. Showcase examples include open source software, open access publishing, massive open online courses (MOOCs), and creative commons licensing. The rise of the internet is a showcase example built on many openly available elements, such as the open TCP/IP and the world-wide web protocols, the Linux operating system, the Wikipedia knowledge base, and media uploaded on social networks. The movement is obviously software driven, but its key relationship to software engineering is more subtle. First, it concerns the development of software that integrates open IP and innovation models based on it. Second, it concerns the treatment of many open IP artifacts (e.g. 3D models, MOOC curricula, or legislation) as software in order to benefit from existing and new software development practices [Spi15]. These include collaboration models (e.g. based on configuration management systems and open source software processes), modularization, and the development of reusable components (e.g. Wikipedia’s templates). In short, the challenge here is to broaden software engineering theory and practices into the domain specific engineering of all digital artifacts.
Massive open online courses, offer free education to all through the internet. The underlying software of MOOCs is not comparable in complexity to that of, say, autonomous vehicles.
However, both developments are equally capable to transform society. Software can have a major role here through the development of authoring platforms and delivery systems that integrate the development of content authoring with assessment, personalization, specialization, and localization. Furthermore, given the rising opportunities and needs for software development, MOOCs can act as enablers for increasing the number of domain experts and end-users that participate in it. Thus the research challenge here is the use of MOOCs to democratize software engineering.
 The Internet of Things (IoT) is driven by the ubiquity and connectivity of sensors and actuators, either as bespoke devices, such as a temperature sensor, or as complete intelligent systems, such as a smartphone. The IoT can provide intelligence to cities, homes, factories, supply chains, and retail shops and thus transform business and everyday life. Two key software related challenges associated with the IoT are the development of architectures, reusable components, and applications that work with peer to peer and intermittent networking connectivity and the development of systems that can harness and exploit the massive amount of data that the IoT generates.
The Internet of Things (IoT) is driven by the ubiquity and connectivity of sensors and actuators, either as bespoke devices, such as a temperature sensor, or as complete intelligent systems, such as a smartphone. The IoT can provide intelligence to cities, homes, factories, supply chains, and retail shops and thus transform business and everyday life. Two key software related challenges associated with the IoT are the development of architectures, reusable components, and applications that work with peer to peer and intermittent networking connectivity and the development of systems that can harness and exploit the massive amount of data that the IoT generates.

3D printing, also known as additive manufacturing, revolutionizes manufacturing, both at the factory floor through new processes and manufacturable artifacts, and, at the level of businesses and individuals, by increasing the availability and reducing the cost of bespoke parts.
3D printing can profit from improved design, solid modeling, and analysis software frameworks and tools. Furthermore, in common with open IP, the 3D printing ecosystem can benefit by treating 3D models as software thus reusing experience, processes, and tools associated with software engineering. This includes the development frameworks, platforms, and reuse models.
LIFE SCIENCES
The domain of life sciences (LS) is extremely broad. It includes large industry sectors, such as pharmaceuticals, health care services, biotechnology, medical technology. Life sciences affect our lives both directly, through the control of human ailments and diseases and indirectly through improved crops and animal health. A lot of progress in the LS field is software-driven, either through the development of algorithms and tools, as in computational biology and bioinformatics or through complete information systems, as in the provision of personalized health care. Software development challenges associated with LS include the management of the field’s gargantuan demand for software, enabling the level of interoperability needed for delivering on many of the field’s promises, handling the massive amounts of generated data, while achieving the required safety, reliability, and protection of personal data.
FINANCIAL TECHNOLOGY
 A number of disruptive innovations and services are changing how financial services are structured, provisioned, and consumed [BLBM15]. Payments, which are increasingly becoming cashless, are on the verge of being transformed through new methods, namely mobile payments and those based on crypto-currency (e.g. the bitcoin protocol and block chain databases). Novel platforms and methods for capital raising (e.g. Kickstarter and IndieGoGo) and peer-to-peer lending lower barriers to entry both for businesses and for investors. In Europe, the revised Payment Services Directive (PSD2) can provide new business opportunities. Traditional capital markets are also changing through the application of big data analytics, machine learning, and new exchange platforms. Insurance is another area facing technology-driven disruption. The risks of insurance are better understood through IoT sensors; for example measuring a car’s speed and acceleration patterns can provide insights on the probability of accidents. Furthermore, online platforms and the sharing economy allow the disaggregation of insurance services; a person’s friends and relatives might have first-hand knowledge of the risks associated with insuring that person, but not the capital required to underwrite them. Block chain databases can also become the basis for the development of decentralized applications in domains other than finance.
A number of disruptive innovations and services are changing how financial services are structured, provisioned, and consumed [BLBM15]. Payments, which are increasingly becoming cashless, are on the verge of being transformed through new methods, namely mobile payments and those based on crypto-currency (e.g. the bitcoin protocol and block chain databases). Novel platforms and methods for capital raising (e.g. Kickstarter and IndieGoGo) and peer-to-peer lending lower barriers to entry both for businesses and for investors. In Europe, the revised Payment Services Directive (PSD2) can provide new business opportunities. Traditional capital markets are also changing through the application of big data analytics, machine learning, and new exchange platforms. Insurance is another area facing technology-driven disruption. The risks of insurance are better understood through IoT sensors; for example measuring a car’s speed and acceleration patterns can provide insights on the probability of accidents. Furthermore, online platforms and the sharing economy allow the disaggregation of insurance services; a person’s friends and relatives might have first-hand knowledge of the risks associated with insuring that person, but not the capital required to underwrite them. Block chain databases can also become the basis for the development of decentralized applications in domains other than finance.
Finally, investment management is affected on the consumer side from social networks and automation and on the provider side through cloud computing. Dependable and robust software lies at the heart of all these changes.
INDUSTRY 4.0
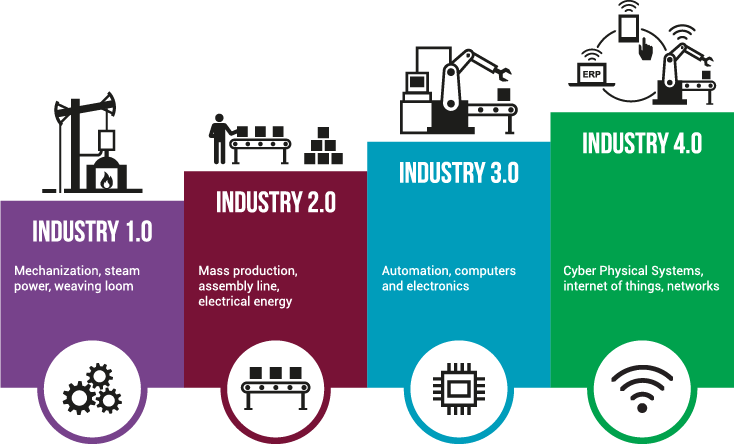 Close integration between the physical world and its IT models, ubiquitous powerful smart sensors and actuators, and distributed controlling software coordinating through a service based model are changing the way factories (and the associated businesses) are organized and operate. The creation of value chains from combining cyber-physical systems, the internet of things, and the internet of services has been termed Industry 4.0. Under it products are still manufactured, but a significant part of their value proposition comes from the provision of a service and through mass customization. Products that fail to follow this trend risk becoming a low-margin commodity, as is currently happening with the contract manufacturing of consumer electronic devices.
Close integration between the physical world and its IT models, ubiquitous powerful smart sensors and actuators, and distributed controlling software coordinating through a service based model are changing the way factories (and the associated businesses) are organized and operate. The creation of value chains from combining cyber-physical systems, the internet of things, and the internet of services has been termed Industry 4.0. Under it products are still manufactured, but a significant part of their value proposition comes from the provision of a service and through mass customization. Products that fail to follow this trend risk becoming a low-margin commodity, as is currently happening with the contract manufacturing of consumer electronic devices.
Software plays a fundamental part in Industry 4.0; the changes associated with it are very much software driven. However, given the industry’s existing rigid and risk-averse setup and stringent safety and reliability requirements the challenges facing the software development are formidable. These include the need to set up wide, agile, and open application development ecosystems while still satisfying the products’ safety and security requirements as well as the need to rapidly develop and evolve software for the app economy. Research to satisfy these needs involves the development of tools and methods that combine agility with reliability and that enable the transformation of physical based processes into virtual ones expressed by software.
SOFTWARE INDUSTRY - CHALLENGES
The technological developments reported in the preceding two sections, together with the convergence of cloud, big data, and software-defined infrastructures (e.g. future networks) create a number of crosscutting challenges in software development. These include the scale and complexity of the underlying computing problems, the necessary tools and abstractions, security and privacy requirements, the development process, and the sustainability of the computing ecosystem.
SCALE AND COMPLEXITY
 Computing systems in the coming years will be considerably larger and more complex than existing ones. In contrast to growth as we have seen it up to now, the rise in scale and complexity will not be mainly driven by the isolated growth of individual systems, but from network effects associated with the combination of diverse data sources and computing devices. Systems of systems will become the norm.
Computing systems in the coming years will be considerably larger and more complex than existing ones. In contrast to growth as we have seen it up to now, the rise in scale and complexity will not be mainly driven by the isolated growth of individual systems, but from network effects associated with the combination of diverse data sources and computing devices. Systems of systems will become the norm.
Consequently, software development has to harness the friction associated with the rising complexity, perhaps by coming up with methods and systems that interoperate in a more fluid manner than existing rigid APIs. This includes building software with components that may turn out to be unreliable and untrustworthy. In the past we have conquered complexity through reusable software modules. In the future we need similar approaches that can conquer the size of data and the complexity of large system configurations, through the establishment of data and system configuration ecosystems and markets. Finally, agile software development, which has delivered significant insights and improvements within some organizations, needs to be scaled up to work across organizational boundaries. This will require rethinking of existing contracting and cooperation practices.
TOOLS AND ABSTRACTIONS
 Progress in tools and abstractions has driven the software industry from its infancy to its current state. Things we now take for granted, such as compilers and object-oriented programming, were once only fledging research results. The new technology-driven challenges must be addressed through the development of suitable programming languages, libraries, frameworks, and architectures as well as testing, debugging, profiling, analysis, and tuning tools. Thankfully, rises in computing and networking capacity allow the realization of approaches that were in the past unrealistically expensive, such as reverse debuggers, microservice architectures, and the individual hardware protection of memory objects.
Progress in tools and abstractions has driven the software industry from its infancy to its current state. Things we now take for granted, such as compilers and object-oriented programming, were once only fledging research results. The new technology-driven challenges must be addressed through the development of suitable programming languages, libraries, frameworks, and architectures as well as testing, debugging, profiling, analysis, and tuning tools. Thankfully, rises in computing and networking capacity allow the realization of approaches that were in the past unrealistically expensive, such as reverse debuggers, microservice architectures, and the individual hardware protection of memory objects.
Harnessing the available hardware resources, building on established software ecosystems, and utilizing advances in theory will continue to be major drivers of progress.
With computing touching every aspect of the daily life, relying on professional developers to deliver the required functionality is unlikely to be enough. This shortage can be addressed through investments in targeted education (e.g. programming bootcamps and MOOCs) as well as through the development of systems, frameworks, APIs, methods, and tools thatallow the implementation of applications by domain experts and end users as well as the creation of powerful mash-apps from existing components.
SECURITY, PRIVACY, AND RELIABILITY
 Many emerging technologies, such as the IoT, and vertical application domains, such as autonomous vehicles, Industry 4.0, and life sciences, strain to their limit our existing approaches for delivering software and systems that are secure, reliable, and respect individual privacy concerns. These areas are orthogonal to each other and recent research suggests that the underlying phenomena are also independent. However, all three share the trait that they effect software and systems (often dramatically) mainly through their absence, rather than their presence. They are also often at odds with each other as well as with other required software attributes, such as usability, functionality, stability, and maintainability.
Many emerging technologies, such as the IoT, and vertical application domains, such as autonomous vehicles, Industry 4.0, and life sciences, strain to their limit our existing approaches for delivering software and systems that are secure, reliable, and respect individual privacy concerns. These areas are orthogonal to each other and recent research suggests that the underlying phenomena are also independent. However, all three share the trait that they effect software and systems (often dramatically) mainly through their absence, rather than their presence. They are also often at odds with each other as well as with other required software attributes, such as usability, functionality, stability, and maintainability.
All the attributes can benefit immensely from the adoption of appropriate architectures, languages, designs, and tools. In particular, the field’s leaders have realized that security and privacy cannot be bolted on after the fact, but must be an integral part of the system’s design.
Therefore, software development research should focus on developing architectures and designs that can inherently deliver the required security and privacy attributes. Sadly, the underlying idea, namely security by design, is more honoured in the breach than the observance. This problem can be addressed through systems-level research into the factors required to adopt the corresponding designs. Progress can also be achieved through the development of tools, such as static and dynamic analysis checkers, libraries, frameworks, languages, and systems that package the functionality in a reusable way, as well as software development processes that demonstrably deliver on those fronts.
SOFTWARE ANALYTICS
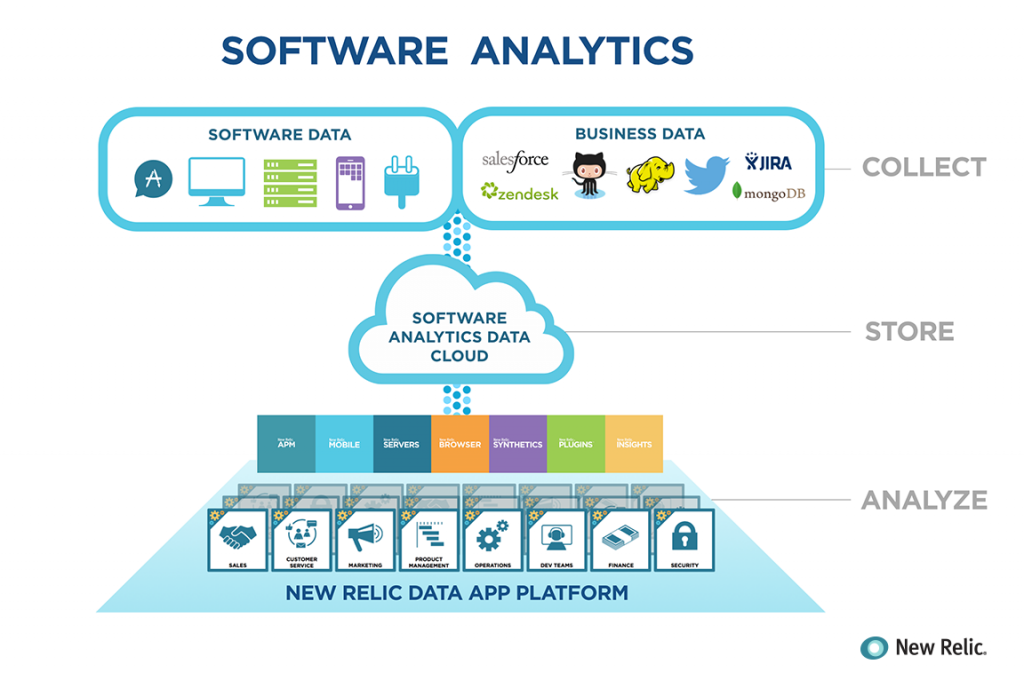 It would be very strange indeed if big data and business analytics did not affect software development. The development and running of software and the operation of computing systems generate (or can be made to generate) immense quantities of data. These concern runtime problems (such as application crashes), test results, performance figures, development process metrics, usage profiles, and subjective experience reports (application reviews). Software engineering can (and should) profit both by developing methods for generating and collecting the appropriate data, and by analyzing the data. Results from this endeavour can improve reliability, usability, development efficiency, and profitability.
It would be very strange indeed if big data and business analytics did not affect software development. The development and running of software and the operation of computing systems generate (or can be made to generate) immense quantities of data. These concern runtime problems (such as application crashes), test results, performance figures, development process metrics, usage profiles, and subjective experience reports (application reviews). Software engineering can (and should) profit both by developing methods for generating and collecting the appropriate data, and by analyzing the data. Results from this endeavour can improve reliability, usability, development efficiency, and profitability.
A lot of work has already been done in this area, but the field is still at its infancy. Important advances are likely to come from the following: the combination of quantitative with qualitative studies; the focus on actionable results that developers can readily use; the combination of static, dynamic , product, and process data; the running of (paid) experiments in realistic production settings; the development of theory based on the analysis; as well as replication studies.
EXTREME COLLABORATION
 The internet has revolutionized many parts of software development. Software package repositories or forges act as central points for gathering and locating reusable software components, and allow the development of sophisticated package managers. These package managers in turn, automatically manage cross-package dependencies, deployment, and updates, thus reducing considerably the burden of software reuse. Most of the underlying components are developed by tens of volunteers as open source software. Consequently, many modern software systems easily contain code written by thousands, giving rise to the phenomenon of extreme collaboration. In a commercial setting this mode of work can be further extended by purposely crowd-sourcing software and content, though several challenges regarding the resulting software quality need to be addressed. Therefore, further research is needed in the handling of cross-platform dependencies and in the management of the required quality attributes in software built from diverse components.
The internet has revolutionized many parts of software development. Software package repositories or forges act as central points for gathering and locating reusable software components, and allow the development of sophisticated package managers. These package managers in turn, automatically manage cross-package dependencies, deployment, and updates, thus reducing considerably the burden of software reuse. Most of the underlying components are developed by tens of volunteers as open source software. Consequently, many modern software systems easily contain code written by thousands, giving rise to the phenomenon of extreme collaboration. In a commercial setting this mode of work can be further extended by purposely crowd-sourcing software and content, though several challenges regarding the resulting software quality need to be addressed. Therefore, further research is needed in the handling of cross-platform dependencies and in the management of the required quality attributes in software built from diverse components.
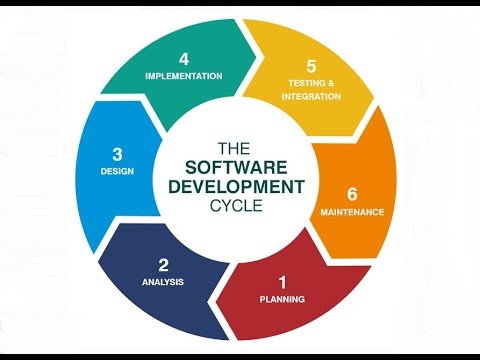 Advances in the software engineering process, from the tight management of each development phase’s deliverables in the 1970s and 1980s to modern agile development approaches, have been agents of progress and change. Further challenges and opportunities lie ahead. These include the continuous delivery and adjustment of software artifacts in the face of changing requirements, software components, telemetry data, user experience intelligence. Another opportunity comes from articulating, managing and adjusting processes to varying risks and rewards. Over the recent years testing has been recognized as an integral element of software development rather than as a separate activity; increasing its effectiveness remains a challenge. Finally, the emergence of software analytics allows us to conduct empirical studies regarding processes, tools, and quality in use that deliver concrete, actionable results with measurable benefits.
Advances in the software engineering process, from the tight management of each development phase’s deliverables in the 1970s and 1980s to modern agile development approaches, have been agents of progress and change. Further challenges and opportunities lie ahead. These include the continuous delivery and adjustment of software artifacts in the face of changing requirements, software components, telemetry data, user experience intelligence. Another opportunity comes from articulating, managing and adjusting processes to varying risks and rewards. Over the recent years testing has been recognized as an integral element of software development rather than as a separate activity; increasing its effectiveness remains a challenge. Finally, the emergence of software analytics allows us to conduct empirical studies regarding processes, tools, and quality in use that deliver concrete, actionable results with measurable benefits.
DEVELOPMENT AND OPERATIONS INTEGRATION
The movement of many software services to cloud infrastructures, has helped us realize that developing software and managing IT infrastructures share commonality and offer important collaboration opportunities. For example, IT professionals use build-like tools to
automate software deployment and infrastructure updates.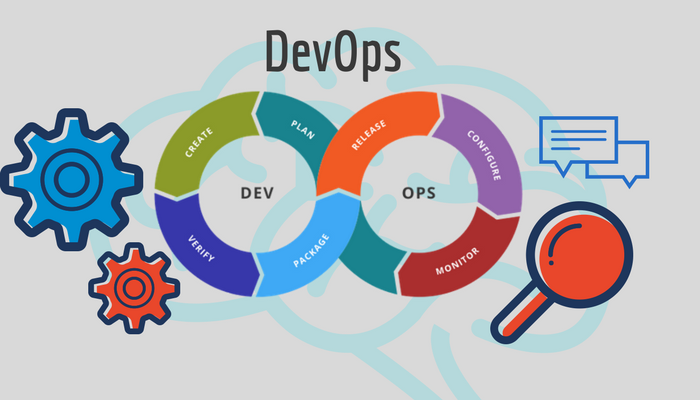
This has given rise to the DevOps movement. Compared to its software engineering sibling, the operations part is still in its infancy in many organizations. Therefore, considerable research is required to bring the corresponding processes, languages, and tools to the level of maturity that we now take for granted in software development. Further research is also likely to deliver considerable benefits in the area of collaboration and sharing of assets among teams.
ENVIRONMENTAL SUSTAINABILITY
 The final horizontal challenge associated with software development research is that of environmental sustainability: the impact of the systems we build on the environment. This includes the energy efficiency of computing and communications systems, the management
of demand and supply for computing at sustainable levels, and a drive toward improved aggregate end-to-end sustainability from components to data centers. Importantly, energy consumption is heavily affected by the software executing on hardware devices. Therefore, research is required into systems that can profile, monitor, and manage energy efficiency from the level of code components to the level of complete data centers.
The final horizontal challenge associated with software development research is that of environmental sustainability: the impact of the systems we build on the environment. This includes the energy efficiency of computing and communications systems, the management
of demand and supply for computing at sustainable levels, and a drive toward improved aggregate end-to-end sustainability from components to data centers. Importantly, energy consumption is heavily affected by the software executing on hardware devices. Therefore, research is required into systems that can profile, monitor, and manage energy efficiency from the level of code components to the level of complete data centers.
Sources: Definition - https://www.businessdictionary.com/definition/software.html Types of Software - https://techspirited.com/major-types-of-software Software Future Trends - https://ec.europa.eu/digital-single-market/en/news/future-trends-and-research-priorities-area-software-technologies
Comments (37 Comments)












































Leave a Reply